vLLM + LWS:Kubernetes 上的多机多卡推理方案
随着 LLM 推理的工程实践不断深入,现有推理框架在部署能力方面的不足日益显现:例如难以跨节点统一管理多个 Pod 的生命周期、资源调度粒度过粗、缺乏分布式拓扑感知等问题。针对这些挑战,Kubernetes 推出了一种新的控制器原语 —— LeaderWorkerSet(简称 LWS),用于支持“分布式启动”“资源组调度”“拓扑感知”“组级原子恢复”等推理服务中的关键能力,成为包括 vLLM、TensorRT-LLM 在内的新一代大模型推理系统的重要运行支撑。
什么是 LWS?
LeaderWorkerSet(LWS)是 Kubernetes 新引入的一个 CRD(CustomResourceDefinition,自定义资源类型),其设计目标是 支持分布式 AI 作业的原生部署与管理,在部署结构上强调以下特点:
- 分布式角色结构:
LWS将一组逻辑相关的Pod分为一个Leader Pod和多个Worker Pod。Leader负责初始化任务、构建主控制流,Worker负责协同工作。 - 统一生命周期管理:
LWS保证一组Pod的创建、销毁、状态检查以“组”为单位统一管理,解决了Deployment、StatefulSet等原生控制器在处理多角色任务时的能力不足。 - 拓扑感知能力:通过对
Node拓扑结构的感知(如GPU、NUMA、TPU拓扑等),LWS能为推理场景中的“低延迟、强绑定”资源调度提供基础。 - 状态同步能力:
Leader可通过注解等机制将服务发现、端口号、共享参数等元信息同步给Worker,降低集群服务编排的复杂性。
简言之,LWS 旨在提供一种 更符合 AI 原生工作负载特点的分布式控制器语义,填补现有原语在推理部署上的能力空白。
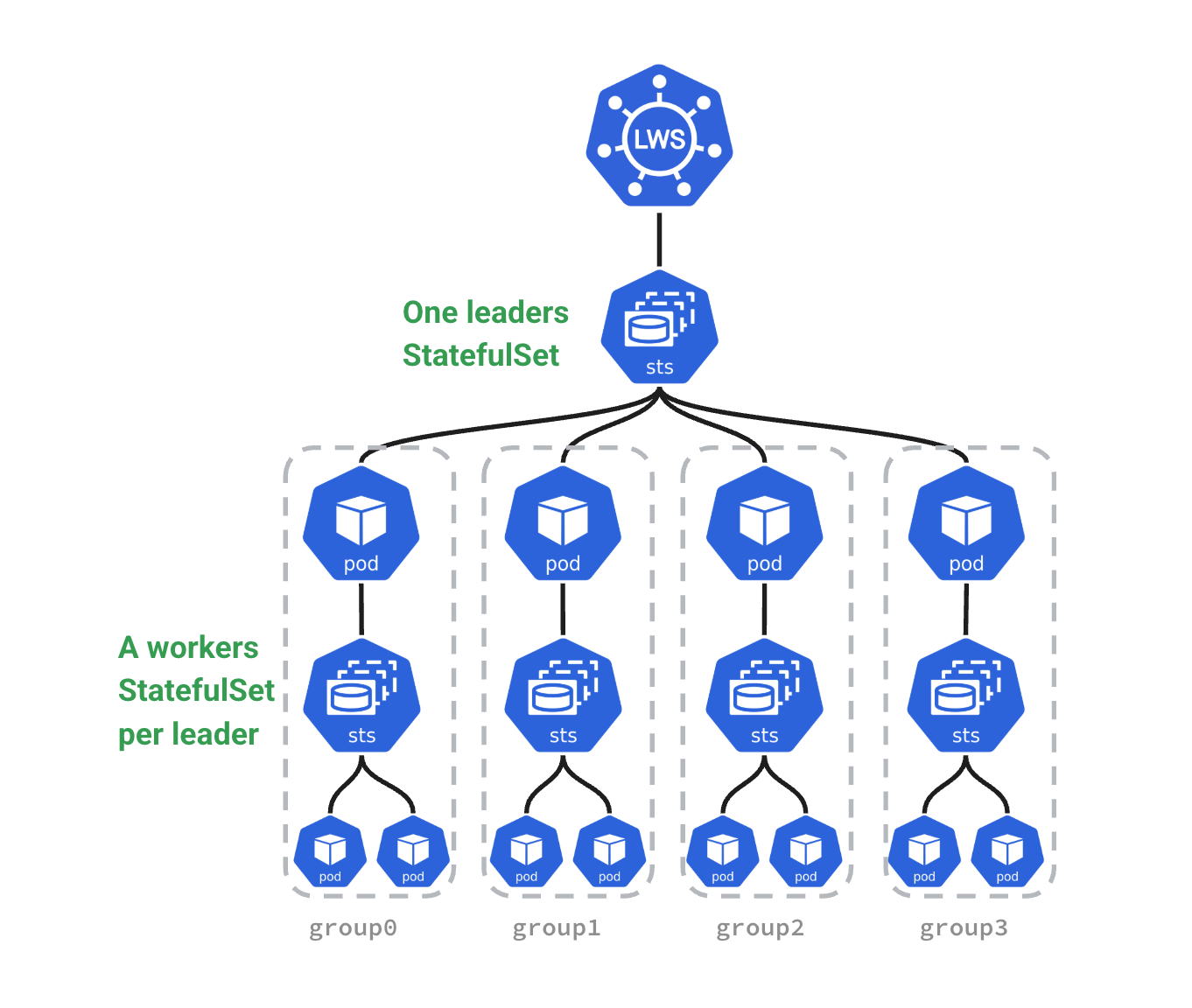
与传统控制器的对比
Kubernetes 中已有多种控制器原语,如 Deployment、StatefulSet、Job、ReplicaSet 等,它们在构建无状态服务或状态服务方面表现出色。然而,对于如 vLLM、TensorRT-LLM 这类 异构资源强绑定 + 启动顺序依赖 + 多节点资源协同 的工作负载,传统原语存在如下不足:
| 控制器 | 适用场景 | 不足 |
|---|---|---|
Deployment / ReplicaSet |
无状态服务(如 Web 服务) | 缺乏角色区分、拓扑感知 |
StatefulSet |
状态服务(如数据库) | 调度粒度为单 Pod,跨节点通信能力弱 |
Job / CronJob |
离线批处理任务 | 不支持长周期常驻服务 |
DaemonSet |
Node 级服务(如日志收集器) | 无法动态扩展,资源调度不可控 |
相比之下,LeaderWorkerSet 是首个支持 Pod 间主从角色语义的控制器,具有以下差异化能力:
- 生命周期一致性:
Leader与Worker被绑定为一个逻辑部署单元,状态同步、重建过程均由控制器原子管理。 - 拓扑表达能力:
Worker可感知Leader所在节点信息,实现“同 NUMA”、“同 switch”等低延迟协同。 - 分布式配置能力:通过注解或
Downward API等方式传递Leader地址、端口、分布式参数,简化调度逻辑。
LWS 的核心优势
1. 统一的生命周期管理
LWS 将 Super Pod 作为原子单元进行扩缩容和更新,确保组内状态一致性。例如:
- 扩缩容时以组为单位增减资源池。
- 滚动更新采用两阶段机制(预热 + 流量切换)。
- 故障时优先局部恢复,必要时整组重建。
2. 拓扑感知的调度
通过 Kubernetes 原生的 Pod Topology Spread Constraints 和厂商扩展实现:
# NVIDIA DGX 系统
annotations:
nvidia.com/gpu.topology: "single-node-socket"
# Google TPU 集群
annotations:
cloud.google.com/gke-tpu-topology: "4x4x4"
支持 NVLink 域内调度、TPU 切片绑定等高级场景,降低跨节点通信延迟。
3. 弹性伸缩与资源优化
与 HPA 深度集成,支持基于多维指标(请求队列、GPU 利用率)的弹性伸缩。资源分配通过 limits/requests 精细化控制,结合 NVIDIA MIG 技术可将单 GPU 划分为多个实例,提升利用率。
4. 安全与可观测性
- 凭证管理:通过
Secrets存储敏感信息,避免明文暴露。 - 网络隔离:使用
NetworkPolicy限制Worker仅允许与Leader通信。 - 监控体系:采集
GPU利用率、KV Cache使用率等关键指标。
vLLM 场景下的能力支撑分析
vLLM 是一个专为大语言模型推理优化的高性能引擎,在实际部署中,它往往要求:
- 横跨多个节点使用 GPU/TPU;
Worker需通过gRPC接入Leader完成分布式KV Cache管理;- 推理参数(如
max num tokens)需由Leader向Worker广播; - 启动与恢复需具备原子性,避免部分
Worker卡死或重连失败。
这些需求中,LWS 提供的组级调度与启动顺序控制能力、拓扑感知能力、配置动态传递能力,恰好能够完整覆盖,如下表所示:
| 能力需求 | LWS 提供方式 |
|---|---|
| 角色区分 | Leader / Worker 模板 |
| 启动顺序 | Leader 先启动,地址写入注解,Worker 自动感知 |
| 参数广播 | Leader 将 tokens、端口等写入 CRD,被 Worker 读取 |
| 拓扑调度 | Worker 可设定和 Leader 相同的 NUMA 区域 |
| 异常恢复 | 控制器统一重启整个组,保证状态一致性 |
vLLM 与 LWS 的实战部署
配置解析
以下是使用 LeaderWorkerSet(LWS)在 Kubernetes 上部署 vLLM 的配置示例:
apiVersion: leaderworkerset.x-k8s.io/v1
kind: LeaderWorkerSet
metadata:
name: vllm
spec:
replicas: 2
leaderWorkerTemplate:
size: 2
restartPolicy: RecreateGroupOnPodRestart
leaderTemplate:
metadata:
labels:
role: leader
spec:
containers:
- name: vllm-leader
image: docker.io/vllm/vllm-openai:latest
env:
- name: HUGGING_FACE_HUB_TOKEN
value: <your-hf-token>
command:
- sh
- -c
- "bash /vllm-workspace/examples/online_serving/multi-node-serving.sh leader --ray_cluster_size=$(LWS_GROUP_SIZE);
python3 -m vllm.entrypoints.openai.api_server --port 8080 --model meta-llama/Meta-Llama-3.1-405B-Instruct --tensor-parallel-size 8 --pipeline_parallel_size 2"
resources:
limits:
nvidia.com/gpu: "8"
memory: 1124Gi
ephemeral-storage: 800Gi
requests:
ephemeral-storage: 800Gi
cpu: 125
ports:
- containerPort: 8080
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
volumeMounts:
- mountPath: /dev/shm
name: dshm
volumes:
- name: dshm
emptyDir:
medium: Memory
sizeLimit: 15Gi
workerTemplate:
spec:
containers:
- name: vllm-worker
image: docker.io/vllm/vllm-openai:latest
command:
- sh
- -c
- "bash /vllm-workspace/examples/online_serving/multi-node-serving.sh worker --ray_address=$(LWS_LEADER_ADDRESS)"
resources:
limits:
nvidia.com/gpu: "8"
memory: 1124Gi
ephemeral-storage: 800Gi
requests:
ephemeral-storage: 800Gi
cpu: 125
env:
- name: HUGGING_FACE_HUB_TOKEN
value: <your-hf-token>
volumeMounts:
- mountPath: /dev/shm
name: dshm
volumes:
- name: dshm
emptyDir:
medium: Memory
sizeLimit: 15Gi
---
apiVersion: v1
kind: Service
metadata:
name: vllm-leader
spec:
ports:
- name: http
port: 8080
protocol: TCP
targetPort: 8080
selector:
leaderworkerset.sigs.k8s.io/name: vllm
role: leader
type: ClusterIP
详细配置说明请参见 vLLM 官方文档。
关键配置说明:
- 动态组规模传递:通过注解机制,
$(LWS_GROUP_SIZE)动态注入组内 Pod 数量,确保资源分配的灵活性。 - 服务发现机制:
WorkerPod 通过注解leaderworkerset.x-k8s.io/leader-address自动获取Leader的地址,实现高效的服务发现。
性能调优与部署实践
vLLM 对推理性能高度敏感,部署时通常采用多机多卡结构(GPU/TPU),以实现模型并行和吞吐优化。以下是某企业在生产环境中的部署经验总结:
- 模型规模:使用
Mixtral模型(12.9B),量化后模型大小约48GB。 - 部署结构:1 个
Leader+ 3 个Worker,每个Worker节点分配 2 块GPU,采用张量并行机制。 -
核心参数调优示例:
python3 -m vllm.entrypoints.openai.api_server \ --model /models/mixtral \ --dtype auto \ --tensor-parallel-size 4 \ --max-model-len 8192 \ --gpu-memory-utilization 0.9 \ --quantization awq \ --enforce-eager \ --max-num-batched-tokens 8192 \ --max-num-seqs 256 \ --disable-log-stats \ --enable-prefetch -
调优要点说明:
--tensor-parallel-size:结合多卡部署设定张量并行维度。--gpu-memory-utilization:控制每张GPU的显存使用上限,避免OOM。--quantization:使用awq量化以减小模型加载体积。--max-num-batched-tokens与--max-num-seqs:控制批处理规模,提升吞吐性能。--enable-prefetch与--enforce-eager:优化执行计划以降低延迟。
该配置可在保持高吞吐的同时,兼顾大模型的响应延迟需求。
未来趋势与能力展望
LWS 仍处于 Alpha 阶段,但其所提供的分布式调度原语被越来越多模型推理系统采纳。在未来,以下方向可能成为演进重点:
- 更强的异构资源调度表达能力:引入
GPU型号、TPU topology-aware等特征调度; - 与 Service Mesh 结合:
Worker动态加入统一负载平衡服务; - 与 HPA(水平自动扩展)协同:根据负载自动调整
Worker数量。
此外,LWS 的控制器机制也可能被扩展用于训练作业、在线增量学习等更广泛的场景中,成为 AI native workload 的基础控制器抽象。
扩展阅读
通过整合 Kubernetes 原生能力与分布式推理优化,LWS 正在重新定义云原生 AI 基础设施的构建范式。其设计理念与实现细节为大规模模型部署提供了重要参考,值得开发者深入探索。