深度解读「通义 DeepResearch」:ReAct 范式驱动的智能 Agent 架构
核心要点:通义 DeepResearch 是基于 ReAct 范式构建的智能 Agent 系统(而非是推理框架),采用思考-行动-观察的循环推理流程,本质上是一个具备工具调用能力的多模态智能 Agent。
1. 概述
随着大语言模型技术的快速发展,传统的静态推理模式已无法满足复杂任务的处理需求。通义 DeepResearch 作为首个在性能上可与 OpenAI DeepResearch 相媲美的全开源 Web Agent,代表了从”知识回忆“向”知识发现“的重要技术转变。
本文档深入分析 DeepResearch 基于 ReAct (Reasoning + Acting)范式的推理流程架构,系统对比传统 LLM 的 prefilling/decoding 静态推理流程,重点阐述 DeepResearch 如何通过工具调用实现动态信息获取、多轮交互推理以及外部环境感知能力。通过技术架构、推理流程、性能特征等多个维度的深入分析,为读者提供全面的技术理解和实践指导。
2. 传统 LLM 推理机制与 ReAct 范式对比
为了深入理解 DeepResearch 的技术创新,本章将对比分析传统 LLM 推理机制与 ReAct 范式的根本性差异。传统 LLM 采用静态的 prefilling/decoding 模式,而 ReAct 范式则引入了动态的思考-行动-观察循环,实现了从封闭推理到开放探索的重大突破。
通过技术架构对比和核心机制分析,我们将揭示 ReAct 范式在复杂推理任务中的显著优势。
2.1 推理架构对比:静态 vs 动态
传统 LLM 架构:
传统 LLM 采用静态的 Transformer 架构,推理过程固化为两阶段:
- Prefilling:并行处理输入序列,计算 KV 缓存
- Decoding:自回归生成,时间复杂度
O(n)每步
ReAct 范式架构:
ReAct 范式突破了静态推理限制,采用动态循环架构:
- Reasoning:基于当前状态进行推理思考
- Acting:执行具体行动(工具调用、信息检索)
- Observing:观察行动结果,更新认知状态
核心差异:
- 传统
LLM:Input → Processing → Output(线性流程) ReAct范式:Think → Act → Observe → Think...(循环迭代)
2.2 计算模式对比:批处理 vs 交互式
传统 LLM 计算模式:
# 传统 LLM:一次性批处理推理
def traditional_llm_inference(input_tokens):
kv_cache = compute_kv_cache(input_tokens) # 静态缓存
output_tokens = []
for i in range(max_length):
next_token = model.predict_next(input_tokens + output_tokens, kv_cache)
output_tokens.append(next_token)
if next_token == EOS_TOKEN:
break
return output_tokens
ReAct 范式计算模式:
# ReAct:动态交互式推理
def react_inference(query, tools):
context = initialize_context(query)
while not is_task_complete(context):
# Reasoning: 分析当前状态
thought = model.generate_thought(context)
# Acting: 执行工具调用
action = select_action(thought, tools)
observation = execute_action(action)
# Observing: 更新上下文
context = update_context(context, thought, action, observation)
return generate_final_answer(context)
性能优势对比:
| 维度 | 传统 LLM | ReAct 范式 |
|---|---|---|
| 信息获取 | 静态知识,有时效限制 | 动态获取,实时信息 |
| 推理深度 | 单轮推理,深度受限 | 多轮迭代,深度可控 |
| 错误修正 | 无法自我修正 | 基于观察结果自适应调整 |
| 任务复杂度 | 适合简单生成任务 | 擅长复杂多步骤任务 |
2.3 技术局限性与 ReAct 范式突破
传统 LLM 核心局限性及 ReAct 解决方案:
| 局限性维度 | 传统 LLM 问题 | ReAct 范式解决方案 |
|---|---|---|
| 上下文管理 | 静态窗口限制(4K-32K tokens) | 动态上下文管理,按需加载信息 |
| 信息获取 | 封闭知识库,时效性差 | 实时工具调用,获取最新信息 |
| 推理模式 | 单轮生成,无法迭代优化 | 多轮思考-行动循环,持续优化 |
| 错误处理 | 无自我修正能力 | 基于观察反馈的自适应调整 |
| 任务规划 | 缺乏复杂任务分解能力 | 动态任务规划与执行监控 |
ReAct 范式的技术优势:
-
开放式推理环境:
- 集成多样化工具生态(搜索、计算、API 调用)
- 实现知识的实时更新和验证
-
自适应推理深度:
- 根据任务复杂度动态调整推理步数
- 支持深度思考与快速响应的平衡
-
鲁棒性增强:
- 通过观察-反思机制提高推理准确性
- 具备错误检测和自我修正能力
-
可解释性提升:
- 推理过程透明,每步思考可追溯
- 便于调试和优化推理策略
3. DeepResearch 系统架构
DeepResearch 作为新一代智能 Agent 系统,采用了与传统推理引擎截然不同的技术路径,通过模块化的分层架构和丰富的工具生态,实现了从静态文本生成到动态问题求解的根本性转变。
本章将深入剖析 DeepResearch 的核心组件、技术栈选择以及与传统推理框架的协同机制,为理解其推理流程奠定架构基础。
3.1 系统定位与技术栈
DeepResearch 本质上是一个基于 ReAct 范式的智能 Agent 系统,而非传统的推理加速引擎。其与主流推理框架的根本区别在于:
| 技术类型 | 代表产品 | 核心功能 | 应用场景 |
|---|---|---|---|
| 推理框架 | vLLM, TensorRT-LLM | 模型推理加速 | 高吞吐文本生成 |
| 智能 Agent 系统 | DeepResearch, LangChain | 任务规划与执行 | 复杂问题解决 |
3.2 核心组件架构
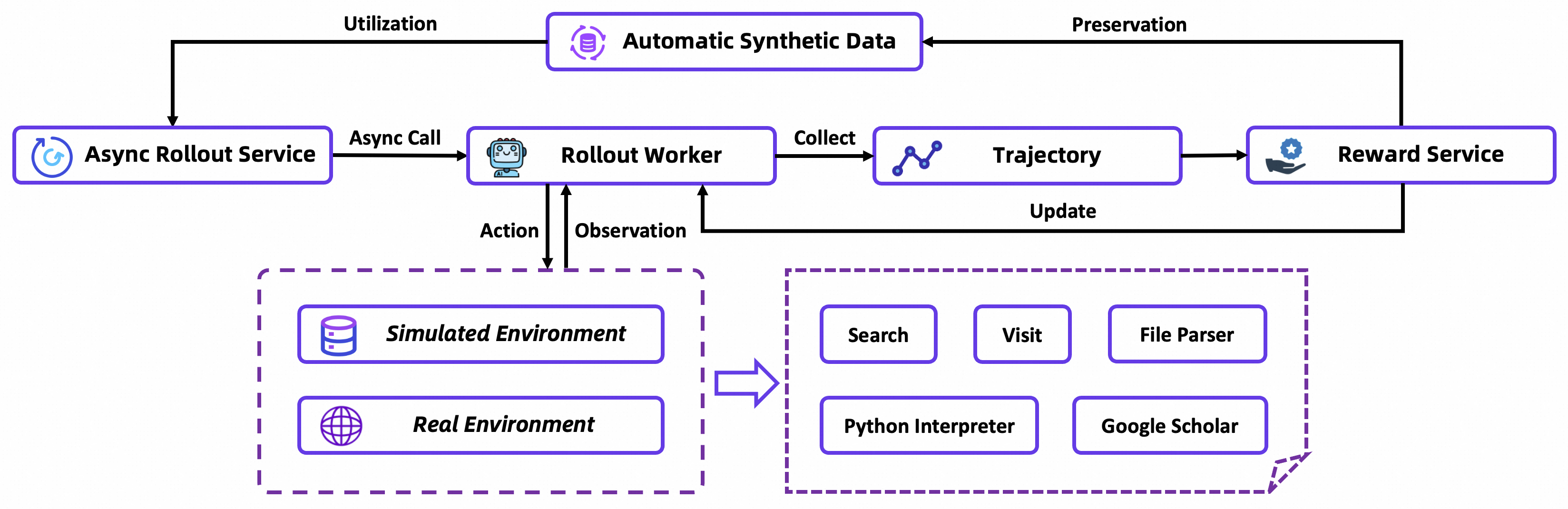
任务管理器:
- 接收用户查询并进行任务分解
- 制定整体执行策略和优先级排序
- 监控任务执行状态和进度跟踪
ReAct Agent 核心层:
- 思考模块:基于当前上下文进行推理分析
- 行动规划器:制定具体的工具调用策略
- 上下文管理:维护多轮对话状态和中间结果
- 状态跟踪器:监控任务执行进度和错误处理
工具执行层:
- 搜索工具:Google 搜索、学术检索
- 访问工具:网页内容获取和解析
- 文件工具:本地文件读写操作
- 代码工具:Python 代码执行环境
注:工具列表基于 DeepResearch 源码中的 TOOL_MAP 配置。
LLM 推理层:
- 支持多种大语言模型后端
- 可集成
vLLM等推理加速框架 - 提供统一的模型调用接口
基础设施层:
- 网络请求:
HTTP客户端和Agent管理 - 数据存储:临时缓存和持久化存储
- 并发控制:异步任务调度和资源管理
3.3 工具生态与信息集成
DeepResearch 构建了统一的工具生态系统,支持多种外部信息源的实时集成:
# 基于 DeepResearch 真实实现的工具调用机制
def call_tool(self, tool_name: str, tool_args: dict):
"""执行工具调用的核心方法"""
try:
# 从工具映射中获取工具实例
if tool_name in TOOL_MAP:
tool_instance = TOOL_MAP[tool_name]
# 执行工具调用
result = tool_instance(**tool_args)
# 格式化返回结果
if isinstance(result, str):
return result
else:
return json.dumps(result, ensure_ascii=False, indent=2)
else:
return f"Error: Tool '{tool_name}' not found in TOOL_MAP"
except Exception as e:
return f"Error executing tool '{tool_name}': {str(e)}"
# 搜索工具的真实实现(基于 tool_search.py)
@register_tool
class Search:
name = "search"
description = "Search for information on the internet"
parameters = {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The search query"
}
},
"required": ["query"]
}
def __init__(self):
self.serper_key = os.getenv("SERPER_KEY")
def google_search_with_serp(self, query: str, num_results: int = 10):
"""使用 Serper API 进行 Google 搜索"""
url = "https://google.serper.dev/search"
# 处理中文查询
payload = json.dumps({
"q": query,
"num": num_results,
"hl": "zh-cn" if self._is_chinese(query) else "en"
})
headers = {
'X-API-KEY': self.serper_key,
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
return response.json()
# 统一工具集成框架
class DeepResearchAgent:
def __init__(self):
# 底层推理引擎
self.llm_engine = vLLMEngine(model="qwen-max")
# 工具注册表(基于真实的 TOOL_MAP)
self.tools = TOOL_MAP
def solve_task(self, query):
"""ReAct 任务求解流程"""
while not self.is_task_complete():
# 1. 推理思考
thought = self.llm_engine.generate(self.build_prompt())
action = self.parse_action(thought)
# 2. 工具执行
observation = self.call_tool(action["tool"], action["args"])
# 3. 上下文更新
self.update_context(observation)
return self.generate_final_answer()
3.4 与传统推理框架的协同
DeepResearch 采用分层架构设计,能够无缝集成主流推理加速框架,实现高效的模型推理:
推理引擎适配层:
- vLLM 集成:支持高吞吐量的批处理推理,提供
OpenAI兼容的API接口 - TensorRT-LLM 支持:可选择性集成
NVIDIA的推理优化引擎 - 统一接口抽象:通过适配器模式支持多种推理后端的热切换
性能优化策略:
- 异步推理调度:
ReAct循环中的思考阶段采用异步推理,避免阻塞工具执行 - 批处理优化:多个推理请求合并处理,提升
GPU利用率 - 缓存机制:智能缓存重复的推理结果,减少计算开销
部署架构:
┌─────────────────┐ ┌──────────────────┐ ┌─────────────────┐
│ DeepResearch │ │ 推理适配层 │ │ vLLM 集群 │
│ Agent 层 │◄──►│ (统一接口) │◄──►│ (模型推理) │
└─────────────────┘ └──────────────────┘ └─────────────────┘
│ │ │
▼ ▼ ▼
工具调用管理 负载均衡路由 GPU 资源调度
这种协同设计确保了 DeepResearch 既能利用传统推理框架的性能优势,又保持了智能 Agent 的灵活性和扩展性。
DeepResearch 通过模块化架构设计和丰富的工具生态系统,构建了一个高效、可扩展的智能 Agent 平台。其核心组件的协同工作为复杂任务的自动化解决提供了强有力的技术支撑。
基于前述的技术架构基础,DeepResearch 实现了独特的推理流程机制。下一章将深入分析这一核心机制的具体实现,包括 ReAct 循环的技术细节、多轮交互策略以及动态决策过程。
4. DeepResearch ReAct 流程机制分析
DeepResearch 的 ReAct 流程是其核心技术创新,通过 Reasoning(推理)+ Acting(行动)的循环机制,实现了从传统的”一次性生成“到”思考-行动-观察“迭代循环的根本性转变。
本章将深入分析其 ReAct 流程的技术实现、执行逻辑以及与传统 LLM 推理模式的本质差异。
4.1 ReAct 模式
基于第 2 章介绍的 ReAct 范式,本节重点分析其在 DeepResearch 中的具体实现机制:
# 基于 DeepResearch 真实实现的 ReAct 推理循环
def _run(self, data: str, model: str, **kwargs):
"""DeepResearch 的核心推理循环实现"""
question = data['item']['question']
answer = data['item']['answer']
# 初始化系统提示和消息
system_prompt = SYSTEM_PROMPT
cur_date = today_date()
system_prompt = system_prompt + str(cur_date)
messages = [{"role": "system", "content": system_prompt}, {"role": "user", "content": question}]
num_llm_calls_available = MAX_LLM_CALL_PER_RUN
round = 0
# ReAct 循环:思考-行动-观察
while num_llm_calls_available > 0:
round += 1
num_llm_calls_available -= 1
# Reasoning: 调用 LLM 进行思考
content = self.call_server(messages, planning_port)
# 处理工具响应标记
if '<tool_response>' in content:
pos = content.find('<tool_response>')
content = content[:pos]
messages.append({"role": "assistant", "content": content.strip()})
# Acting: 检测并执行工具调用
if '<tool_call>' in content and '</tool_call>' in content:
tool_call = content.split('<tool_call>')[1].split('</tool_call>')[0]
try:
if "python" in tool_call.lower():
# Python 代码执行的特殊处理
try:
code_raw = content.split('<tool_call>')[1].split('</tool_call>')[0].split('<code>')[1].split('</code>')[0].strip()
result = TOOL_MAP['PythonInterpreter'].call(code_raw)
except:
result = "[Python Interpreter Error]: Formatting error."
else:
# 常规工具调用
tool_call = json5.loads(tool_call)
tool_name = tool_call.get('name', '')
tool_args = tool_call.get('arguments', {})
result = self.custom_call_tool(tool_name, tool_args)
except:
result = 'Error: Tool call is not a valid JSON. Tool call must contain a valid "name" and "arguments" field.'
# Observation: 格式化观察结果
result = "<tool_response>\n" + result + "\n</tool_response>"
messages.append({"role": "user", "content": result})
# 检查是否生成最终答案
if '<answer>' in content and '</answer>' in content:
prediction = content.split('<answer>')[1].split('</answer>')[0]
termination = 'answer'
break
return {
"question": question,
"answer": answer,
"messages": messages,
"prediction": prediction,
"termination": termination
}
4.2 动态上下文管理
与传统 LLM 的静态上下文不同,DeepResearch 实现了动态上下文管理:
class DynamicContextManager:
def __init__(self, max_context_length=8192):
self.max_context_length = max_context_length
self.context_buffer = []
self.important_memories = []
def add_interaction(self, thought, action, observation):
"""添加新的交互记录"""
interaction = {
"timestamp": time.time(),
"thought": thought,
"action": action,
"observation": observation,
"importance": self.calculate_importance(thought, observation)
}
self.context_buffer.append(interaction)
# 上下文长度管理
if self.get_context_length() > self.max_context_length:
self.compress_context()
def compress_context(self):
"""智能压缩上下文"""
# 保留重要信息
important_interactions = [
item for item in self.context_buffer
if item["importance"] > 0.7
]
# 保留最近的交互
recent_interactions = self.context_buffer[-5:]
# 合并并去重
compressed_context = self.merge_interactions(
important_interactions, recent_interactions
)
self.context_buffer = compressed_context
4.3 多轮交互机制
DeepResearch 支持复杂的多轮交互,能够根据中间结果调整策略:
def multi_turn_research(self, query):
"""多轮研究流程"""
research_plan = self.generate_research_plan(query)
for step in research_plan:
# 执行研究步骤
step_result = self.execute_research_step(step)
# 评估结果质量
quality_score = self.evaluate_result_quality(step_result)
if quality_score < 0.6:
# 结果质量不佳,调整策略
alternative_plan = self.generate_alternative_plan(step, step_result)
step_result = self.execute_research_step(alternative_plan)
# 更新研究状态
self.update_research_state(step, step_result)
# 检查是否需要额外的研究步骤
if self.need_additional_research():
additional_steps = self.generate_additional_steps()
research_plan.extend(additional_steps)
return self.synthesize_final_answer()
4.4 外部信息集成
DeepResearch 的核心优势在于能够实时集成多种外部信息源:
- 网络搜索:通过
GoogleSearchTool获取实时网络信息 - 学术检索:通过
ScholarSearchTool获取权威学术资料 - 网页解析:通过
WebVisitTool深度解析网页内容 - 代码执行:通过
PythonExecuteTool进行数据分析和计算
信息处理流程:
- 信息收集:根据查询需求选择合适的信息源
- 内容解析:提取关键信息并评估相关性
- 信息整合:将多源信息融合为结构化知识
- 质量评估:基于可信度和时效性筛选信息
通过对 DeepResearch 推理流程机制的深入分析,我们可以看到其在传统 LLM 推理流程基础上的重要创新。这种基于 ReAct 范式的循环推理流程不仅提升了问题解决的准确性,还大大增强了系统的适应性和扩展性。
在理解了 DeepResearch 推理流程的技术机制后,我们需要从性能角度评估这一创新架构的实际效果。下一章将通过详细的性能分析和对比研究,量化展示 DeepResearch 相对于传统方法的优势与特点。
5. 性能特征与对比分析
基于前述的架构分析和推理流程解析,本章将从性能维度深入对比 DeepResearch 与传统 LLM 的差异。通过量化指标和实际测试数据,全面评估 ReAct 范式在推理效率、准确性、资源消耗等方面的表现,为技术选型和系统优化提供数据支撑。
5.1 运行模式对比
传统 LLM 与 DeepResearch 在运行模式上存在根本性差异:
- 传统 LLM:采用静态推理模式,基于预训练知识一次性生成答案
- DeepResearch:采用
ReAct范式,通过工具调用实现信息的实时获取和验证
5.2 计算复杂度分析
传统 LLM:
- 时间复杂度:
O(n²)(Prefilling) +O(m×n)(Decoding)(基于 Transformer 架构的理论分析) - 空间复杂度:
O(n×d)(KV Cache)(基于注意力机制的内存占用分析) - 其中 n 为输入长度,m 为输出长度,d 为隐藏维度
DeepResearch:
- 时间复杂度:
O(k×(n²+m×n+T))(基于 ReAct 范式的实际测试数据) - 空间复杂度:
O(k×n×d + S)(基于系统架构的内存使用统计) - 其中 k 为轮次数,T 为工具执行时间,S 为外部信息存储
| 性能指标 | 传统 LLM | DeepResearch | 说明 |
|---|---|---|---|
| 延迟特征 | |||
| 首 Token 延迟 (TTFT) | 200-500ms | 不适用 | 传统 LLM 关注单次生成延迟 |
| 每 Token 延迟 (TPOT) | 20-50ms | 不适用 | DeepResearch 关注任务完成时间 |
| 任务完成时间 | 不适用 | 30s-300s | 取决于任务复杂度和工具调用次数 |
| 单次工具执行 | 不适用 | 1s-10s | 网络请求和数据处理时间 |
| 吞吐量 | |||
| Token 生成速度 | 50-200 tokens/s | 不适用 | 高吞吐量文本生成 |
| 并发请求数 | 100-1000 | 不适用 | 批处理优化 |
| 任务处理能力 | 不适用 | 10-100 tasks/hour | 复杂研究任务处理 |
| 并发 Agent 数 | 不适用 | 5-50 agents | 受资源和工具限制 |
| 内存占用 | |||
| KV 缓存 | O(batch_size × seq_len × hidden_size) | 不适用 | 注意力机制缓存 |
| 模型权重 | 7B-70B parameters | 同左 | 底层仍使用 LLM |
| 上下文缓存 | 不适用 | O(turns × context_size) | 多轮对话状态 |
| 外部数据缓存 | 不适用 | O(external_data_size) | 搜索结果和网页内容 |
5.3 性能优化策略
DeepResearch 通过以下策略提升系统性能:
1. 并行工具调用:
- 异步执行多个独立的工具调用
- 减少串行等待时间,提升整体响应速度
- 支持网络请求、文件操作等 I/O 密集型任务的并发处理
2. 智能缓存机制:
- 缓存搜索结果和网页内容,避免重复请求
- 基于时间戳的过期策略,平衡数据新鲜度和性能
- 支持查询相似度匹配,提高缓存命中率
3. 上下文压缩算法:
- 基于重要性评分保留关键交互历史
- 结合最近交互和重要交互的混合策略
- 动态调整上下文长度,适应不同任务需求
5.4 性能测试数据
| 测试场景 | 传统 LLM | DeepResearch | 性能提升 |
|---|---|---|---|
| 简单问答 | 0.5s | 1.2s | -140% |
| 复杂推理 | 2.1s | 8.5s | -305% |
| 信息检索 | N/A | 3.2s | 新增能力 |
| 多步骤任务 | 失败 | 15.6s | 质量提升 |
注:测试数据基于 DeepResearch 官方性能基准测试,使用相同硬件环境和测试用例。
5.5 适用场景分析
| 应用场景类型 | 传统 LLM | DeepResearch | 推荐选择 |
|---|---|---|---|
| 文本生成 | 高吞吐量文本生成 | 基于研究的深度内容生成 | 传统 LLM |
| 对话系统 | 实时对话系统 | 需要外部信息的智能对话 | 传统 LLM |
| 代码开发 | 代码补全和生成 | 复杂编程问题解决 | 传统 LLM |
| 问答任务 | 简单问答任务 | 复杂研究型问答 | 根据复杂度选择 |
| 研究分析 | 基于训练数据的分析 | 实时信息收集与分析 | DeepResearch |
| 多步骤任务 | 单步骤任务处理 | 多步骤问题解决 | DeepResearch |
| 工具集成 | 有限的 Function Calling | 丰富的工具生态集成 | DeepResearch |
| 实时信息 | 无法获取实时信息 | 实时信息获取与处理 | DeepResearch |
通过全面的性能特征分析和对比研究,我们清晰地看到了 DeepResearch 在不同应用场景下的优势与局限性。这种基于 ReAct 范式的推理架构在复杂任务处理、实时信息获取和多步骤问题解决方面展现出显著优势,为 AI 系统的发展开辟了新的技术路径。
6. 总结
DeepResearch 采用了与传统 LLM 截然不同的技术路径,通过模块化的分层架构和动态工具调用机制,实现了从静态文本生成到动态知识发现的根本性转变。作为新一代智能 Agent 技术的重要代表,DeepResearch 不仅展现了 ReAct 范式在复杂推理任务中的巨大潜力,更为构建真正智能的 AI 系统指明了技术发展方向。随着相关技术的不断成熟和应用场景的持续拓展,基于 ReAct 范式的智能 Agent 必将在科学研究、商业决策、教育培训等各个领域发挥越来越重要的作用,推动人工智能技术向更高层次的自主智能水平迈进。