Knowledge Graphs for RAG(GraphRAG)
本教案基于 DeepLearning.AI 与 Neo4j 合作的 “Knowledge Graphs for RAG” 课程设计,旨在为学习者提供从理论到实践的完整路径 [1]。课程围绕构建一个基于 SEC 10-K 年度报告的问答系统展开,通过实战掌握 GraphRAG 的核心技术。本教案涉及检索增强生成(Retrieval-Augmented Generation, RAG)、知识图谱(Knowledge Graph, KG)与大语言模型(Large Language Model, LLM)等概念。
课程信息
- 课程名称: Knowledge Graphs for RAG (GraphRAG)
- 适用人群: AI 工程师、数据科学家、希望提升 RAG 系统性能的开发者
- 先决条件:
- 熟悉 Python 编程
- 了解基本的 LLM 和 LangChain 概念
- 拥有 OpenAI API Key(或其他可用 LLM 服务的 API Key)
- 已安装 Docker(用于运行 Neo4j)
- 学习目标:
- 理解知识图谱(KG)如何解决传统 RAG 的上下文缺失问题。
- 掌握 Neo4j 图数据库的基本操作与 Cypher 查询语言。
- 学会使用 LangChain 将非结构化文本转化为结构化图谱(Text2Graph)。
- 构建一个结合向量检索与图检索的混合检索(Hybrid Retrieval) QA 系统。
课程大纲
| 模块 | 主题 | 核心内容 | 建议时长 |
|---|---|---|---|
| Module 1 | 基础理论与环境搭建 | KG 概念、GraphRAG 优势、Neo4j Docker 部署 | 1 小时 |
| Module 2 | Cypher 查询语言入门 | 节点、关系、属性、MATCH/RETURN 语句 | 1.5 小时 |
| Module 3 | 非结构化文本的图谱构建 | Text2Graph 流程、Schema 定义、LLM 提取 | 2 小时 |
| Module 4 | 混合检索与问答系统 | 向量索引、图谱检索、LangChain 集成 | 2 小时 |
| Module 5 | 实战项目:SEC 财报分析 | 处理真实 10-K 数据、多文档关联、复杂推理 | 2.5 小时 |
以上时长为教学设计的建议值,可根据学员基础与实践深度进行调整。
详细教学内容
Module 1: 基础理论与环境搭建
1.1 理论:为什么需要 GraphRAG?
- 传统 RAG 的局限性:
- 切片(Chunking)导致语义断裂: 简单的文本切分可能将实体与其属性或关系分开。
- 缺乏全局视角: 无法回答跨文档或跨段落的综合性问题(例如:”A 公司的供应商 B 的高管 C 之前在哪工作?”)。
- 知识图谱的优势:
- 显式关系: 直接存储实体间的连接。
- 结构化上下文: 提供更精准的上下文窗口,减少幻觉。
1.2 环境搭建 (Hands-on)
任务: 启动 Neo4j 数据库并配置 Python 环境。
-
启动 Neo4j (Docker):
# 启动 Neo4j 并启用 APOC 插件(示例配置) docker run \ --name neo4j-graphrag \ -p 7474:7474 -p 7687:7687 \ -e NEO4J_AUTH=neo4j/password \ -e NEO4J_PLUGINS='["apoc"]' \ neo4j:5.18.0- 访问
http://localhost:7474验证启动成功。
- 访问
-
安装 Python 依赖:
# 安装本教案示例所需的核心依赖 pip install langchain langchain-community langchain-openai langchain-experimental neo4j tiktoken
Module 2: Cypher 查询语言入门
2.1 核心概念
- Node (节点): 实体,如
(p:Person {name: "Elon Musk"}) - Relationship (关系): 连接,如
[:FOUNDED {year: 2002}] - Label (标签): 类别,如
:Person,:Company
2.2 基础查询练习
场景: 电影数据库。
-
创建数据:
CREATE (m:Movie {title: "The Matrix", released: 1999}) CREATE (p:Person {name: "Keanu Reeves", born: 1964}) CREATE (p)-[:ACTED_IN {roles: ["Neo"]}]->(m) -
查询数据:
// 查找 Keanu Reeves 演过的电影 MATCH (p:Person {name: "Keanu Reeves"})-[:ACTED_IN]->(m:Movie) RETURN m.title, m.released
课后练习
- 编写 Cypher 语句,创建一个包含 “User” 和 “Product” 的简单购买关系图。
Module 3: 非结构化文本的图谱构建 (Text2Graph)
这是本课程的核心。我们将使用 LLM 自动从文本中提取实体和关系。
3.1 流程图解
graph LR
%% Text2Graph:从非结构化文本构建知识图谱的最小流程
A[非结构化文档] --> B[文本切片 - Chunks]
B --> C{LLM - Graph Transformer}
C --> D[提取节点 & 关系]
D --> E[(Neo4j 数据库)]
3.2 实战代码:从文本到图谱
步骤:
- 定义 Schema: 告诉 LLM 我们关心哪些类型的节点和关系。
- 执行提取: 使用 LangChain 的
LLMGraphTransformer。
在运行示例代码前,先在终端设置必要的环境变量:
export OPENAI_API_KEY="your_api_key" # LLM 服务的 API Key
export NEO4J_URI="bolt://localhost:7687" # Neo4j Bolt 连接地址
export NEO4J_USERNAME="neo4j" # Neo4j 用户名
export NEO4J_PASSWORD="password" # Neo4j 密码
import os
from langchain_community.graphs import Neo4jGraph
from langchain_openai import ChatOpenAI
from langchain_experimental.graph_transformers import LLMGraphTransformer
from langchain_core.documents import Document
required_env = ["OPENAI_API_KEY", "NEO4J_URI", "NEO4J_USERNAME", "NEO4J_PASSWORD"]
missing_env = [k for k in required_env if not os.getenv(k)]
if missing_env:
raise RuntimeError(f"Missing env vars: {', '.join(missing_env)}")
graph = Neo4jGraph()
# 示例文本
text = """
Apple Inc. is an American multinational technology company headquartered in Cupertino, California.
Tim Cook is the CEO of Apple.
"""
documents = [Document(page_content=text)]
# 初始化转换器 (GPT-4 效果最佳)
llm = ChatOpenAI(temperature=0, model="gpt-4")
llm_transformer = LLMGraphTransformer(
llm=llm,
allowed_nodes=["Company", "Person", "City"],
allowed_relationships=["HEADQUARTERED_IN", "CEO_OF", "LOCATED_IN"]
)
# 转换并存储
graph_documents = llm_transformer.convert_to_graph_documents(documents)
graph.add_graph_documents(graph_documents)
first_graph_document = next(iter(graph_documents))
print(f"提取了 {len(first_graph_document.nodes)} 个节点和 {len(first_graph_document.relationships)} 条关系。")
Module 4: 混合检索与问答系统
4.1 混合检索架构
单纯的图检索可能漏掉非结构化的细节,单纯的向量检索缺乏结构。混合检索结合两者。
- 向量检索 (Vector Search): 寻找语义相似的文档块。
- 图检索 (Graph Traversal): 寻找实体及其邻居。
4.2 实现 QA Chain
注意:GraphCypherQAChain 具备从自然语言生成 Cypher 的能力,若允许执行不受控的写操作或危险查询,可能带来数据破坏风险。示例中默认关闭危险请求;生产环境建议结合只读账号、查询白名单与审计策略。
可参考 Neo4j GenAI 相关工具栈与 LangChain 的 Neo4j 集成文档 [3,4]。
from langchain.chains import GraphCypherQAChain
# 自动将自然语言转为 Cypher
chain = GraphCypherQAChain.from_llm(
graph=graph,
llm=llm,
verbose=True,
allow_dangerous_requests=False
)
# 提问
response = chain.invoke({"query": "Who is the CEO of the company located in Cupertino?"})
print(response['result'])
Module 5: 实战项目:SEC 财报分析
背景: 投资者需要分析大量的 SEC 10-K 表格(年度报告),了解公司的风险、高管和投资关系。
5.1 数据准备
- 下载示例 SEC 10-K JSON 数据(如 NetApp Inc. 的财报)。
- 提取其中的
Item 1(Business) 和Item 1A(Risk Factors) 部分。 - 资源: 完整的数据处理脚本、Notebooks 及示例数据可在 GitHub 仓库中找到 [2]。
5.2 构建策略
- Chunking: 将长文本切分为块(例如 500-1000 tokens,需根据模型上下文窗口与任务调整)。
- 向量化: 为每个 Chunk 创建向量索引,存入 Neo4j。
- 图谱化: 提取关键实体(如
Manager,Company,Product)。 - 连接: 将 Chunk 节点链接到提取出的实体节点(
MENTIONS关系)。
5.3 复杂查询示例
问题: “NetApp 提到了哪些关于供应链的风险?”
- 检索路径:
- 向量检索: 搜索 “supply chain risk” 相关的 Chunk 节点。
- 图扩展: 查找这些 Chunk 关联的
Risk实体。 - 生成: LLM 综合这些信息生成回答。
常见问题 (FAQ)
- Q: 必须使用 GPT-4 吗?
- A: 推荐使用 GPT-4 进行图谱提取(Text2Graph),因为它对指令的遵循能力更强,能生成更规范的 Schema。问答阶段可以使用 GPT-3.5 或其他模型。
- Q: 如何处理实体消歧(Entity Resolution)?
- A: 比如 “Apple” 和 “Apple Inc.”。可以在提取后使用简单的规则合并,或者在提取前给 LLM 提供明确的命名规范。
- Q: 数据量很大怎么办?
- A: 对于大规模数据,建议并行处理 Text2Graph 步骤,并使用 Neo4j 的批量导入工具。
拓展思考
RAG 与 GraphRAG:区别与联系
传统 RAG(Retrieval-Augmented Generation)的核心思想是:将语料切分为 Chunks,为每个 Chunk 构建向量索引;在用户提问时,通过相似度检索召回 Top-K 文本片段,将其拼接到 Prompt 中交给 LLM 生成答案。其优势是工程落地快、可扩展性强,但在以下场景中容易遇到瓶颈:
- 跨 Chunk 依赖:实体、属性与关系分散在多个片段中,Top-K 召回未必能同时覆盖关键上下文。
- 多跳推理:问题需要沿实体关系做 2 跳及以上推理时,纯向量相似度检索往往难以稳定召回完整链路。
- 全局一致性:当语料规模变大,Chunk 粒度与召回策略的权衡(召回率 vs. 噪声)会更显著影响回答质量。
GraphRAG 可以视为 RAG 的一种“结构增强”范式:它在保留向量检索优势的同时,引入图结构来显式表达实体关系与层次结构,并在检索阶段加入图扩展、路径/子图检索等图感知机制,从而提升多跳推理与上下文保持能力 [5,6]。从构建方式上,GraphRAG 常见两类工作流:
- Knowledge-based GraphRAG:从语料中抽取实体与关系,构建“事实型”知识图谱,并用子图作为检索与生成依据。
- Index-based GraphRAG:将语料摘要为主题节点形成“索引图”,并将主题与原始文本片段建立映射,实现结构化导航与事实回链。
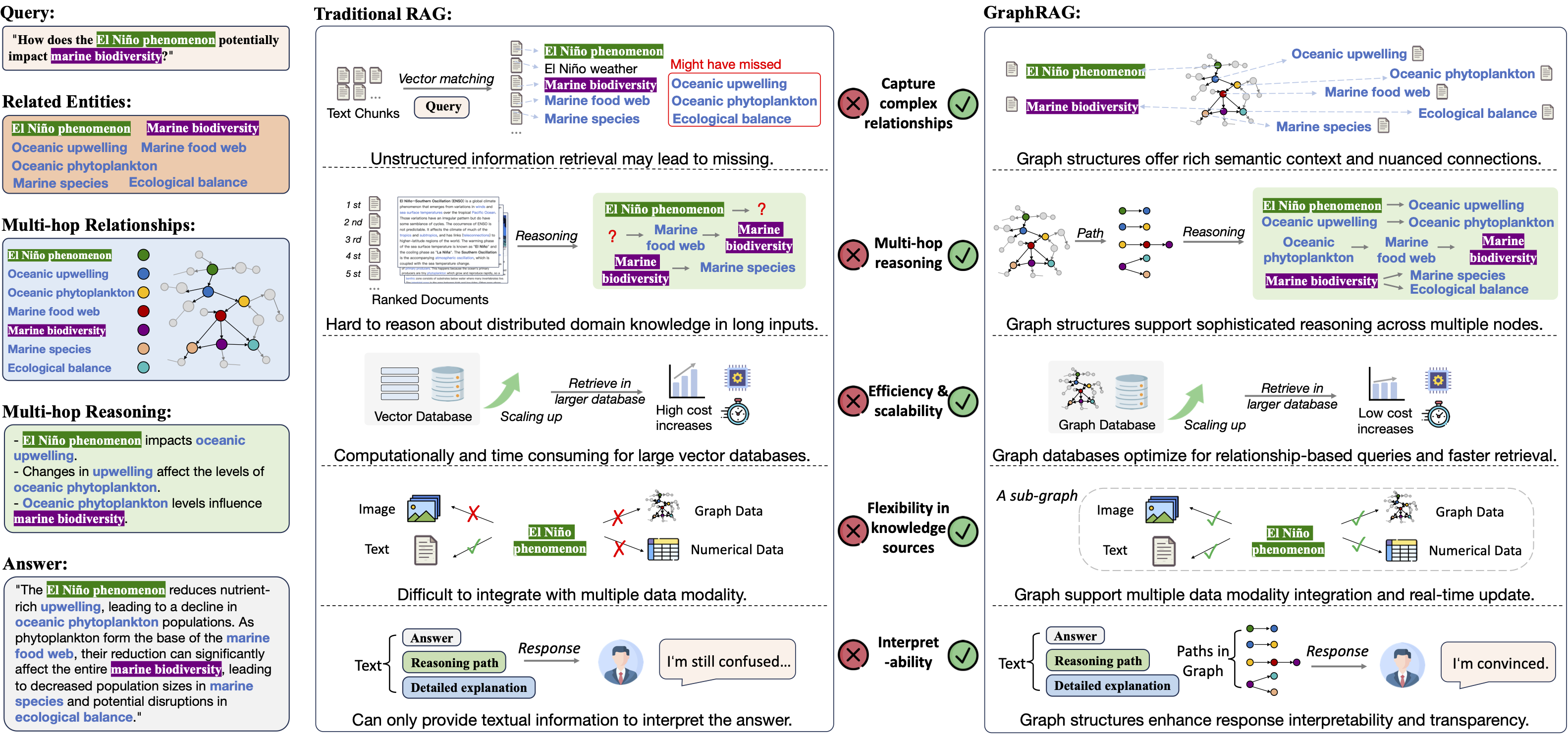
图 1. RAG 与 GraphRAG 的典型工作流对比(来源:Awesome-GraphRAG)[5,7]
图中示例问题:”How does the El Niño phenomenon potentially impact marine biodiversity?”(该问题为图示示例,与本文 SEC 10-K 案例无直接对应关系)
GraphRAG vs. Synergized LLMs + KGs
在实际的企业级应用(如银行反欺诈)中,我们常听到 “Synergized LLMs + KGs”(大模型与知识图谱协同)这一概念。虽然它与 GraphRAG 都涉及 KG 和 LLM 的结合,但在设计理念和KG 的角色上有显著区别。
| 维度 | GraphRAG (本课程模式) | Synergized LLMs + KGs (如银行反欺诈) |
|---|---|---|
| 核心目标 | 文档问答与检索增强。解决 LLM 在长文本、跨文档信息上的遗忘和幻觉问题。 | 复杂推理与决策支持。解决高风险场景下的精确性、可解释性和实时性问题。 |
| KG 的来源 | 主要来自非结构化文本 (Text2Graph)。KG 是为了更好地索引文本而临时或半自动构建的。 | 主要来自结构化业务数据 (Core Banking System)。KG 是核心资产,包含高质量、经校验的账户、交易、设备信息。 |
| KG 的质量 | 概率性。依赖 LLM 提取,可能存在噪声、错误或不完整的关系。 | 确定性 (High Quality)。作为 “Ground Truth” (事实基准),数据的准确性至关重要。 |
| LLM 的角色 | 构建者 & 接口。LLM 既用于构建图谱,也用于生成最终的自然语言回答。 | 推理者 & 解释者。LLM 利用高质量 KG 进行逻辑推理 (Reasoning) 和结果解释,而非构建基础事实。 |
| 典型场景 | 研报分析、法律文档审查、百科问答。 | 资金链路追踪、团伙挖掘、反洗钱 (AML)。 |
总结:
- 本课程教授的 GraphRAG 更多关注如何”从无到有”利用 LLM 将文本转化为图谱,以提升检索效果。
- Synergized LLMs + KGs 则更多关注如何”强强联合”,利用已有的高质量图谱为 LLM 提供可靠的推理边界和事实依据。
参考文献与资源
[1] DeepLearning.AI. “Knowledge Graphs for RAG.” DeepLearning.AI. 访问日期:2025-12-25. [Online]. Available: https://learn.deeplearning.ai/courses/knowledge-graphs-rag/
[2] Kaushik Acharya. “Knowledge_Graphs_for_RAG.” GitHub. 访问日期:2025-12-25. [Online]. Available: https://github.com/kaushikacharya/Knowledge_Graphs_for_RAG
[3] Neo4j. “neo4j/neo4j-genai-python.” GitHub. 访问日期:2025-12-25. [Online]. Available: https://github.com/neo4j/neo4j-genai-python
[4] LangChain. “Neo4j Cypher (Graphs Integration).” LangChain Documentation. 访问日期:2025-12-25. [Online]. Available: https://python.langchain.com/docs/integrations/graphs/neo4j_cypher/
[5] DEEP-PolyU. “Awesome-GraphRAG.” GitHub. 访问日期:2025-12-25. [Online]. Available: https://github.com/DEEP-PolyU/Awesome-GraphRAG
[6] Zhang, Q., Chen, S., Bei, Y., Yuan, Z., Zhou, H., Hong, Z., Dong, J., Chen, H., Chang, Y., & Huang, X. “A Survey of Graph Retrieval-Augmented Generation for Customized Large Language Models.” arXiv preprint arXiv:2501.13958, 2025. [Online]. Available: https://arxiv.org/abs/2501.13958
[7] DEEP-PolyU. “rag_vs_graphrag.png.” Awesome-GraphRAG. 访问日期:2025-12-25. [Online]. Available: https://raw.githubusercontent.com/DEEP-PolyU/Awesome-GraphRAG/main/figs/rag_vs_graphrag.png