在 Elasticsearch 之上实现一个虚拟文件系统
来源:Leonie Monigatti – Implementing a virtual filesystem over Elasticsearch
发布时间:2026 年 5 月 5 日
让 Agent 能够在 Elasticsearch 之上使用 grep 与 cat。
本文介绍如何在持久化数据存储(例如 Elasticsearch 数据库)之上实现一个虚拟文件系统,以便让 AI Agent 能够访问 grep、cat 等 Shell 命令。
本页目录
大语言模型(LLM)在海量的 Shell 会话和代码库上进行过训练,因此 Agent 天然擅长使用 CLI 并在文件系统中导航。
最近一篇介绍 LangSmith Agent Builder 记忆系统如何构建在文件系统之上的博客引发了一场关于”文件系统是否就是你需要的一切”的讨论。LangChain CEO、同时也是该博客作者的 Harrison Chase 随后澄清:他们实际上并没有把数据存储在真实的文件系统中,而是存在一个数据库里,只是以文件系统的形式暴露给 Agent 使用。几周后,Mintlify 也描述了他们如何在已有数据库之上构建一个虚拟文件系统,通过 just-bash 库让 Agent 可以运行 cat、ls、grep 和 find。
译者注(非原文):读到这里,不妨沿着作者的思路再往前追两问。
Agent 到底需要什么样的接口来访问”上下文”?一套文件系统接口是否足以覆盖数据、记忆、工具调用等所有场景? 文件系统作为抽象层有两个天然优势:一是 LLM 在海量 Shell 语料上预训练过,
ls/cat/grep几乎可以零样本学会;二是”路径 + 字节流”的语义极简,几乎什么存储都能往里套——同样一个grep,底层可以是倒排索引、SQLLIKE、正则,甚至向量相似度或外部搜索 API;同样一个cat,背后可以是一个文件、一行数据库记录,或一次语义召回。本文的ElasticsearchFs就演示了这种解耦:对外保持 POSIX 语义,对内把grep拆成”ES 粗筛 + JS RegExp 精筛”两阶段。但”对外同一套命令”并不等于”这套接口就真的够用”——为了真正撬动底层的多样能力,命令本身往往需要扩展参数:grep对接向量检索时,是不是要加--semantic开关、--top-k/--min-score才能表达”语义相近但字面不同”?对接结构化存储时,是不是要加--field/--filter才能表达 schema 维度?再往记忆与工具调用场景推:记忆系统需要时效性、重要性与召回率的联合调度,cat /memory/user-prefs.mdx究竟该返回原始条目、一次摘要,还是最近一次语义召回?工具调用本质上是带 Schema 的 RPC,”参数校验失败”这种错误又如何塞进ENOENT/ENOTDIR/EROFS这套 POSIX 错误码?一旦命令开始长出”感知后端”的参数、一旦文件语义开始承载调度策略,这到底还算一套”统一的文件系统接口”,还是一层伪装成 POSIX 的专用 DSL?从这个意义上讲,文件系统更像是一个统一的”门面(façade)”,而未必是底层最合适的抽象——真正的设计张力,在于”命令可扩展到哪一步,仍然是 Agent 能零样本复用的 POSIX 直觉,而不是另一门需要重新学习的查询语言”。目前有哪些组织在推动”Agent 世界访问接口”的标准化? 这里需要先做一个关键区分:Anthropic 主导的 Model Context Protocol (MCP)、Google 的 A2A (Agent-to-Agent) 以及 OpenAI Function Calling 这类 Tool Use 规范,解决的主要是 “语法层” 的问题——它们规定了”如何描述一个工具、如何调用、如何回传结果、如何在 Agent 之间传递消息”,更像是”英语的语法”:语法稳定了,但词汇表(具体有哪些工具)仍然要在运行时作为 Prompt 塞给模型,LLM 本身并不知道你手里到底有什么工具。这条路径能让生态互操作,却并没有消除”每次对话都得先把 tools schema 贴给模型”这个前提。更贴近本文主题、也更值得追问的,是另一个方向——能不能定义一套像 POSIX 文件接口那样小而稳定、且能被基础模型在预训练中直接内化的”世界访问词汇表”? 一旦这样一套原语足够标准、足够高频,Agent 就不再需要把 tools 描述喂给 LLM,LLM 凭世界模型本身的先验就能直接给出 tool call——就像它今天敲
ls/cat/grep从来不需要你先告诉它”这台机器上有这三个命令”一样。本文的ElasticsearchFs其实就是这种思路的一个微缩样本:它挑了一组 LLM 早已在 Shell 语料里烂熟的命令,作为 Agent 访问 Elasticsearch 的默认接口,顺手省掉了运行时”把工具 schema 贴给模型”的那一步。换句话说,MCP / A2A 回答的是”怎么说“,而我们真正缺的是一层”说什么“的共识——一组像 POSIX 那样有限、正交、能被预训练直接吃进去的原语。这也恰是”世界模型 → 世界访问接口”这条路径的工程含义:世界模型让 Agent 理解世界长什么样;统一且可预训练的访问接口,决定它能否”不被告知”就知道怎么操作世界——前者靠数据与规模,后者靠生态在”词汇表”层面达成共识。
受这些博客启发,本文探索如何在 Elasticsearch 之上实现一个虚拟文件系统。这是一个概念验证(POC)实现,目标是尽可能贴近 Mintlify 博客中描述的架构。ElasticsearchFs 的最终实现可以在 iamleonie/elasticsearch-fs 找到。
什么是面向 Agent 的”虚拟文件系统”
“虚拟文件系统”这一术语传统上用于操作系统语境。在操作系统中,虚拟文件系统是一个抽象层,无论程序读取的是 SSD、U 盘还是网络共享,都可以使用相同的 open、read、write 调用。
在 AI Agent 的语境下,虚拟文件系统指的是在持久化存储(例如关系型数据库、向量库,或本文中的 Elasticsearch)之上构建的、形似文件系统的接口。它让 Agent 可以对存储的数据使用 ls、cat、find 和 grep。当 Agent 执行 grep -r "access_token" /docs 时,它认为自己正在搜索一个文件系统,并不知道背后交互的其实是一个搜索索引。因此,grep 这样的命令就变成了一层接口,其实现可以利用强大的搜索能力,比如向量检索或混合检索。
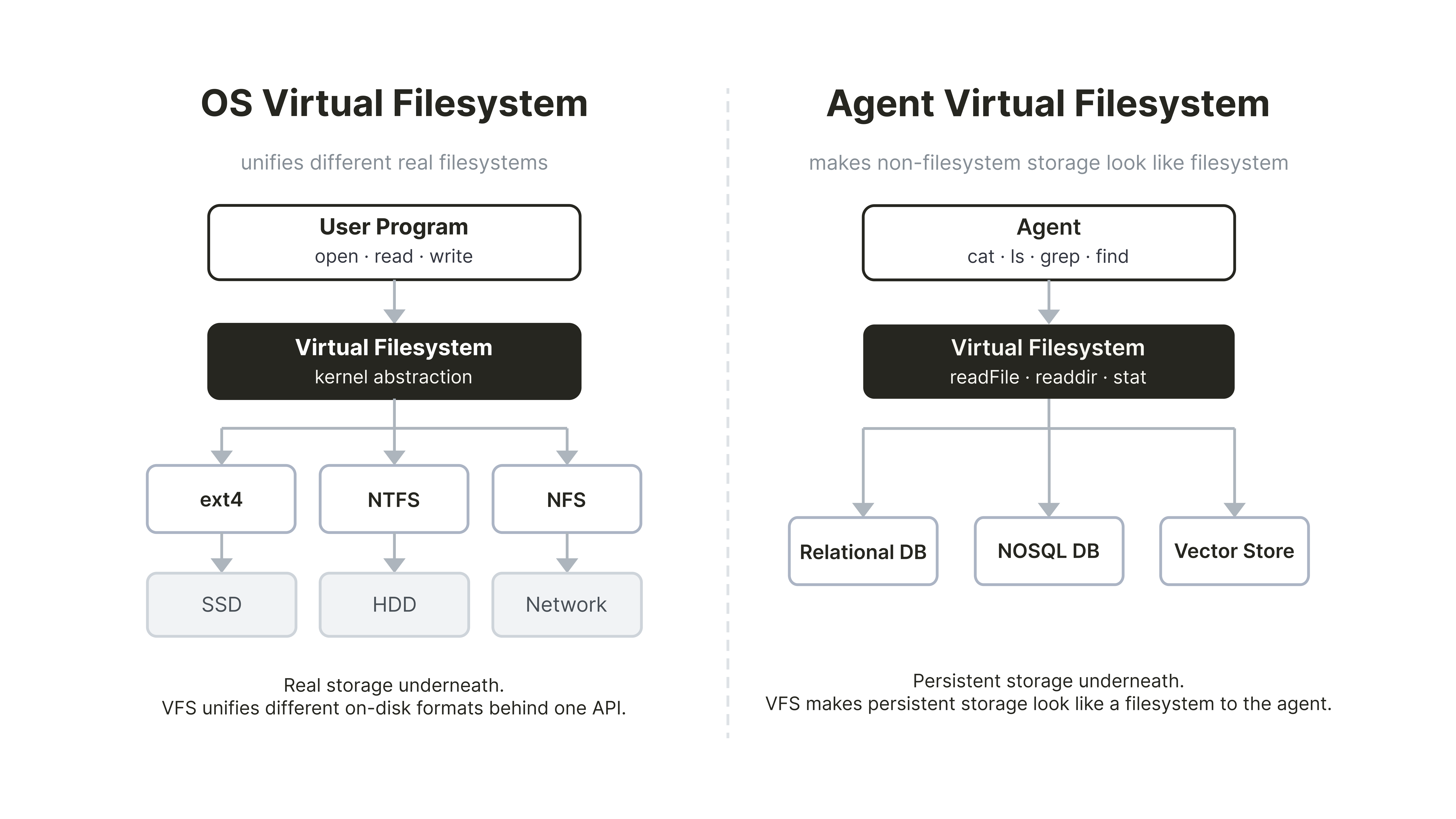
架构总览
ElasticsearchFs 虚拟文件系统的最终实现包含四层,与 Mintlify 博客类似:
- Agent 层: LLM Agent 通过工具调用发出 Shell 命令。
- Shell 层:
just-bash是一个 TypeScript 库,负责拦截这些 Shell 命令字符串,解析选项、处理管道,并分发到IFileSystem接口。 ElasticsearchFs层: 基于下层数据层实现IFileSystem接口。- 数据层: 数据存储在一个 Elasticsearch Serverless 集群中。
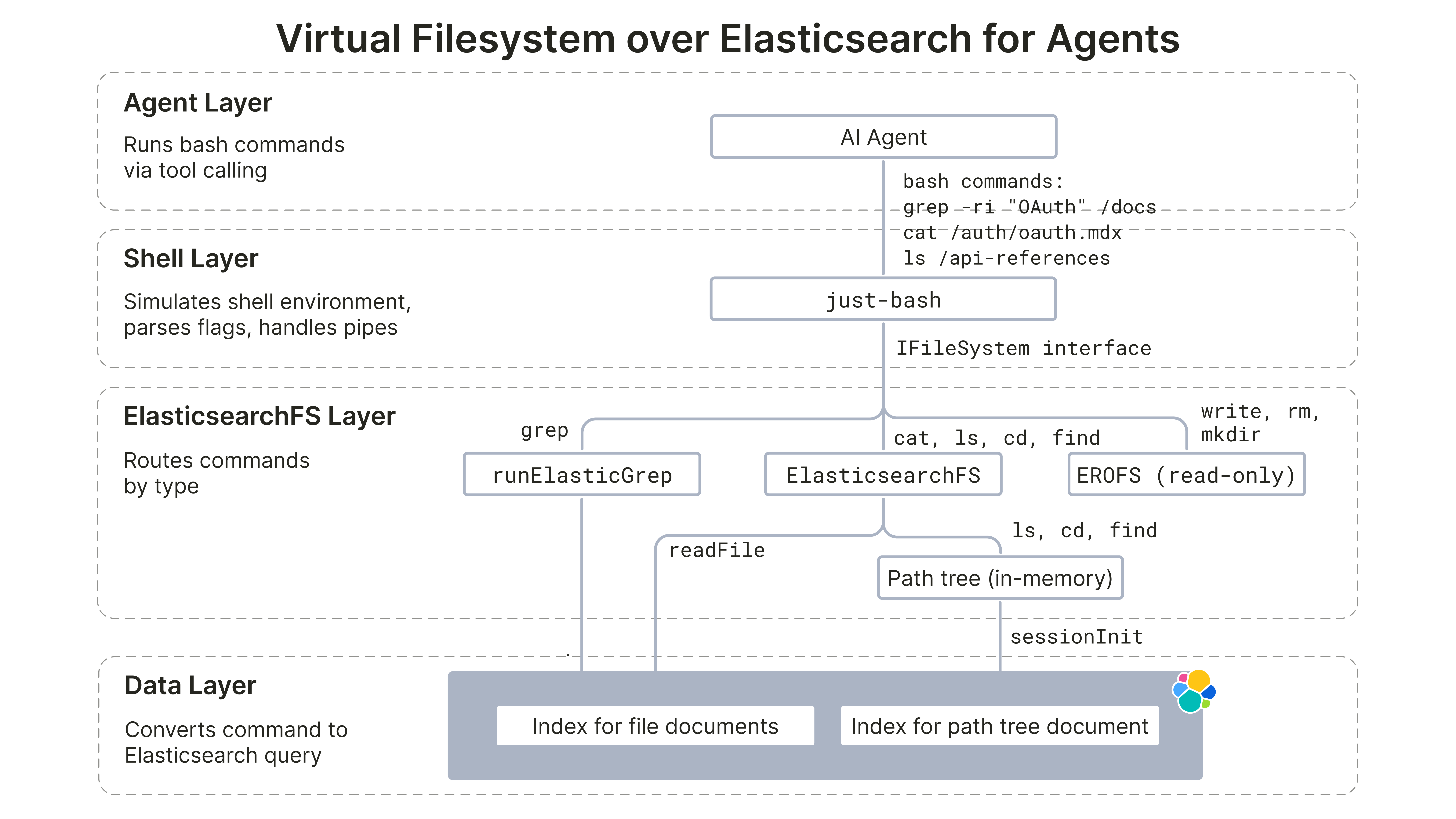
“面向 AI Agent、构建在数据库(Elasticsearch)之上的虚拟文件系统”。
除了遵循 Mintlify 博客中描述的实现方式之外,我们还参考了 LangChain 文档中关于虚拟文件系统的设计准则:
- 绝对路径的处理与归一化。 所有路径均为绝对路径。
normalizePath会在执行任何树查找或 Elasticsearch 调用之前,对 Agent 传入的路径进行规范化(例如auth/oauth会被归一化为/auth/oauth)。 - 高效实现
ls与glob(在服务端支持的情况下采用服务端过滤,否则使用本地过滤)。 这两个操作在会话启动后完全在内存中完成,不会产生任何 Elasticsearch 调用。 - 显式处理错误: LangChain 的准则建议使用带有 error 字段的结构化结果类型来表达文件缺失或无效模式等错误。由于我们的实现构建在
just-bash之上,所以这里采用了 POSIX 风格的ErrnoException(ENOENT、ENOTDIR、EROFS)。此外,我们沿用 Mintlify 的只读设计,因此任何写操作都会抛出EROFS。
实现细节
整个实现划分为四个方面:访问控制、文件系统导航、文件读取以及文件搜索。完整实现可在 elasticsearch-fs 仓库中查看。
通过 DLS 实现访问控制
ElasticsearchFs 将文件访问控制委托给 Elasticsearch 的文档级安全(Document Level Security,DLS)机制:每个查询都会附加到一个 Elasticsearch 角色上,该角色下发起的所有请求都会在检索时被该查询自动过滤。这样一来,访问检查在数据层对每一个查询路径都生效,降低了意外数据泄漏的风险。
在本 POC 实现中,我们参考了 Mintlify 博客中的路径树策略形态,定义了三个角色:PUBLIC、BILLING 与 INTERNAL,同时额外增加了一个用于数据摄入的 SYSTEM 角色。
| 路径 | PUBLIC | INTERNAL | BILLING | SYSTEM |
|---|---|---|---|---|
| /auth/oauth.mdx | x | x | x | x |
| /auth/api-keys.mdx | x | x | x | x |
| /internal/billing.mdx | - | x | x | x |
| /internal/audit-log.mdx | - | x | - | x |
| /api-reference/users.mdx | x | x | x | x |
| /api-reference/payments.mdx | - | - | x | x |
| /api-reference/search-use-case/* | x | x | x | x |
这些角色在 Serverless 项目中被创建,并通过以下方式设置权限后绑定到一个 API Key:
{
"PUBLIC": {
"cluster": [],
"indices": [
{
"names": ["elasticsearchfs-chunks"],
"privileges": ["read"],
"query": {
"bool": {
"should": [
{ "prefix": { "slug": "auth/" } },
{ "prefix": { "slug": "api-reference/search-use-case/" } },
{ "term": { "slug": "api-reference/users" } }
],
"minimum_should_match": 1
}
}
},
{
"names": ["elasticsearchfs-meta"],
"privileges": ["read"]
}
]
}
}
ls、cd、find:文件系统导航
ElasticsearchFs 的启动流程与 Mintlify 博客中类似。数据摄入步骤会向元数据索引(elasticsearchfs-meta)中写入一份 __path_tree__ 文档,每个会话在启动时首先加载该文档。
// 从元数据索引中获取预构建好的路径树文档
const doc = await client.get({
index: "elasticsearchfs-meta",
id: "__path_tree__",
});
// 将 base64 负载解码并解析为路径树对象
const json = Buffer.from(payload, "base64").toString("utf8");
const pathTree = JSON.parse(json);
随后,系统根据所选的运行时配置(PUBLIC、BILLING、INTERNAL、SYSTEM)对 isPublic 和 groups 进行校验,并据此修剪这棵路径树来解析可见性。这意味着 BILLING 会话永远不会列出 /internal/audit-log.mdx,而对该路径的探测会返回 ENOENT,因为在按该角色裁剪过的树中这个路径并不存在。
可见的 slug 会被转换为两个紧凑的结构:
Set<string>:所有规范文件路径的集合Map<string, string[]>:从目录路径映射到其子节点名称。
会话初始化完成后,ls、cd、find 全都是在这份内存状态之上进行的树遍历操作,无需再查询 Elasticsearch。ls 从 dirs 中读取直接子节点;cd 校验目标目录在该映射中是否存在;find 则递归遍历 dirs 图,同时在 files 中检查叶子路径。
cat:读取文件
读取文件是一次单独的 Elasticsearch 调用。当 Agent 执行 cat /auth/oauth.mdx 时,just-bash 会调用 readFile,后者将路径解析为 slug auth/oauth 并以此在 Elasticsearch 中查询:
async readFile(path: string): Promise<string> {
// 将路径解析为 Elasticsearch 中使用的 slug
const slug = this.resolveReadFileSlug(path);
// 按 slug 在文件索引中检索 content 字段
const results = await this.client.search<FileHitSource>({
index: ELASTICSEARCHFS_FILES_INDEX,
size: 1,
_source: ['content'],
query: {
bool: {
filter: [{ term: { slug } }],
},
},
});
// 取第一条命中,若 content 不存在则抛出 ENOENT
const hit = results.hits.hits[0];
const content = hit?._source?.content;
if (content === undefined) {
throw enoent();
}
return content;
}
此外,resolveReadFileSlug 会在发起任何网络调用之前,先以 ENOTDIR 拒绝目录路径、以 ENOENT 拒绝未知路径。
grep:两阶段优化
与 Mintlify 类似,我们对 grep 的实现采用了两阶段优化,因为一个朴素的 grep -r 会通过网络读取所有作用域内的文件。just-bash 的 defineCommand 钩子允许我们注册一个自定义 grep,从而实现两阶段 grep 优化。自定义 grep 会接收到原始的 argv Token,我们使用 yargs-parser 对其进行解析。
第一阶段(粗筛)首先通过在数据库上运行一次搜索查询来缩小候选集。根据模式的形态,它会为字面量模式或正则模式选择不同的查询类型。
字面量模式(-F / --fixed-strings,或不包含正则元字符的模式)会被拆分为两种粗筛查询形态。首先,忽略大小写的字面量(-i)对 content 使用 match_phrase:
{
"query": {
"bool": {
"filter": [{ "terms": { "slug": ["<slugs-in-scope>"] } }],
"must": [{ "match_phrase": { "content": "<literal-pattern>" } }]
}
}
}
另一方面,区分大小写的字面量则使用对转义后字面量的 regexp 查询,作用在 content.pattern 上:
{
"query": {
"bool": {
"filter": [{ "terms": { "slug": ["<slugs-in-scope>"] } }],
"must": [
{
"regexp": {
"content.pattern": {
"value": ".*(<escaped-literal-pattern>).*",
"case_insensitive": false
}
}
}
]
}
}
}
正则模式则对 content.pattern 使用 regexp 查询,该字段是一个 wildcard 多字段。注意,在 content 字段上也可以使用 regexp,但只支持 term 级别的匹配。
{
"query": {
"bool": {
"filter": [{ "terms": { "slug": ["<slugs-in-scope>"] } }],
"must": [
{
"regexp": {
"content.pattern": {
"value": ".*(<regex-pattern>).*"
}
}
}
]
}
}
}
在第二阶段(精筛)中,每一个候选 slug 都会通过 readFile 被读取。读取到的内容会按行切分,每一行都会被一个已编译的 RegExp 匹配(对于固定字符串模式,则使用简单的 includes 检查)。
// 粗筛:向底层存储询问匹配字符串/正则的 slug 集合
const matchedSlugs = await elasticsearchFs.findMatchingFiles(
coarseFilter,
slugsUnderDirs,
);
// 若没有候选 slug,直接返回空结果并以 exit code 1 结束
if (matchedSlugs.length === 0) return { stdout: "", stderr: "", exitCode: 1 };
// 精筛:将 slug 还原为可读文件路径
const matchedPaths = matchedSlugs.map((slug) => slugToPath(slug));
// 执行:交由内存中的 RegExp 引擎格式化最终输出
return execBuiltin(
scannedArgs,
matchedPaths,
elasticsearchFs,
shouldPrefixFilePath,
);
已知局限
作为一个 POC 实现,本方案存在以下已知局限:
- 粗筛的 grep 可能产生漏报。 粗筛阶段使用的是 Elasticsearch/Lucene 的正则语法,而精筛阶段使用的是 JavaScript
RegExp。这种语法差异可能在到达精筛验证之前就产生漏报。 - 没有批量预取(bulk-prefetch)。 Mintlify 的 grep 粗筛阶段会先在数据存储中识别候选文件,再在进入精筛之前将所有匹配的分块批量加载到缓存中,从而让大规模递归查询能在毫秒级完成。而
ElasticsearchFs是通过readFile逐个读取候选文件的,没有进程内缓存。 stat返回的是占位元数据。size始终为0,mtime始终为 epoch ——stat不会发起任何 Elasticsearch 调用。会话启动时只会加载路径树元数据(不包含每个文件的时间戳/大小);虽然文档上存在updated_at,但本实现并未将其物化到内存树中。实际后果是:ls -l、find -mtime与find -size的结果并不真实。- 仅支持
.mdx文件类型。 路径树仅按/<slug>.mdx建立索引,其他扩展名的文件无法在树中表示,对 Agent 来说不可见。
上手试用
你可以按如下方式使用这个基于 Elasticsearch 的虚拟文件系统:
import { ElasticsearchFs } from "../src/core/elasticsearchfs.js";
import { runElasticGrep } from "../src/core/grep.js";
import { Bash, defineCommand } from "just-bash";
import { createESClient } from "../src/es-adapter/client.js";
import { initSessionTree } from "../src/session.js";
// 1. 用用户角色初始化 ES 客户端
const profile = "PUBLIC";
const client = createESClient(profile);
// 2. 初始化路径树
const session_tree = await initSessionTree(client, profile);
// 3. 初始化虚拟文件系统
const elasticsearchFs = new ElasticsearchFs({
client: client,
files: session_tree.files,
dirs: session_tree.dirs,
});
// 4. 定义自定义 grep 命令
const grep = defineCommand("grep", async (args, ctx) =>
runElasticGrep(args, ctx, elasticsearchFs),
);
// 5. 在 Elasticsearch 后端之上初始化带自定义 grep 的 Bash 实例
const bash = new Bash({
fs: elasticsearchFs,
cwd: "/",
customCommands: [grep],
});
// 6. 使用示例
await bash.exec('grep -ri "OAuth" /auth');
await bash.exec("cat /auth/oauth.mdx");
await bash.exec("ls /api-reference");
总结
本文实现了 ElasticsearchFs——一个基于 Elasticsearch 的虚拟文件系统。它构建在 just-bash 之上,向 Agent 暴露 cat、ls、cd、find 和 grep,同时将访问控制保持在靠近数据的一层。该 POC 未做过基准测试,目标只是探索架构与实现,而非验证延迟或成本方面的结论。
完整代码见代码仓库。如果要走向更偏生产级的实现,接下来可以考虑的改进方向包括:为 grep 密集型会话中重复的文件读取引入进程内/远程缓存,或者为 grep 提供基于语义检索的替代方案。后者需要额外对文件进行分块,并在查询阶段重新组装。
参考资料
- Mintlify. How we built a virtual filesystem for our assistant
- Vercel Labs.
just-bashGitHub 仓库 - LangChain. Design guidelines: Use a virtual filesystem