KV Cache 原理简介
1. 背景:大模型推理的挑战
在大语言模型(LLM)的推理过程中,尤其是文本生成任务中,模型通常采用自回归(Autoregressive)的方式逐个生成 Token。这种生成机制如果不加以优化,会面临严重的计算效率问题,理解这一基础模式是后续探索性能优化手段的前提。
1.1 自回归生成模式
在自回归生成中,模型根据之前的上下文(Context)预测下一个 Token。例如,给定输入 “Hello”,模型预测 “World”;接着给定 “Hello World”,模型预测 “!”。在没有缓存时,模型必须将 “Hello” 等历史上下文重复编码。这意味着每生成一个新的 Token,模型都需要回顾并重新计算之前所有的 Token。
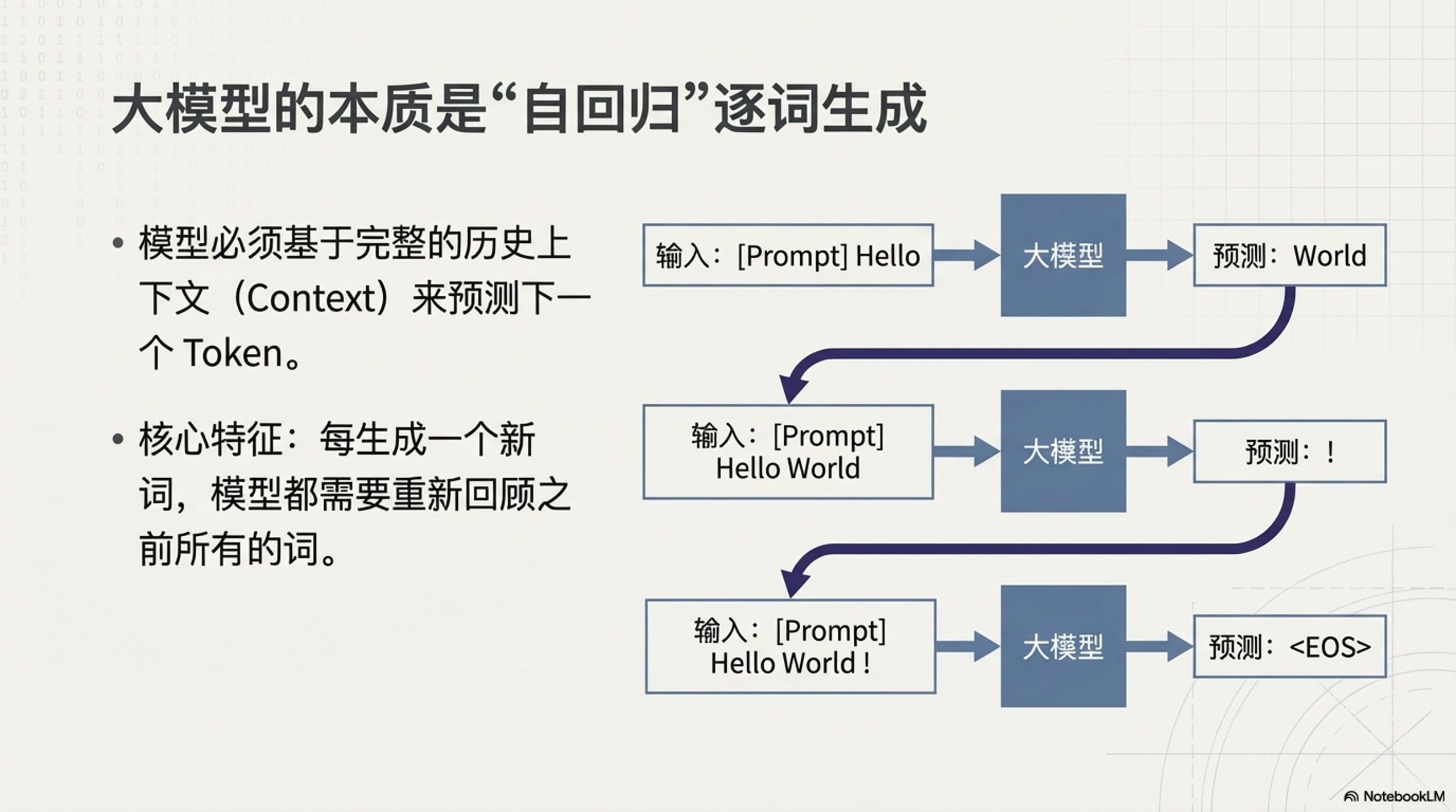
1.2 重复计算问题
如果不使用缓存机制,每生成一个新的 Token,模型都需要将之前所有 Token 重新输入模型,并重新计算它们的 Key (K) 和 Value (V) 矩阵。随着序列长度的增加,这种重复计算若仅看单步前向,无缓存时注意力计算量为 $O(N^2)$,其中 $N$ 为当前序列长度。若考虑从第 1 个 Token 生成到第 $L_{gen}$ 个 Token 的完整过程,累积计算量约为 $O(L_{gen}^3)$,延迟将随生成长度急剧恶化。
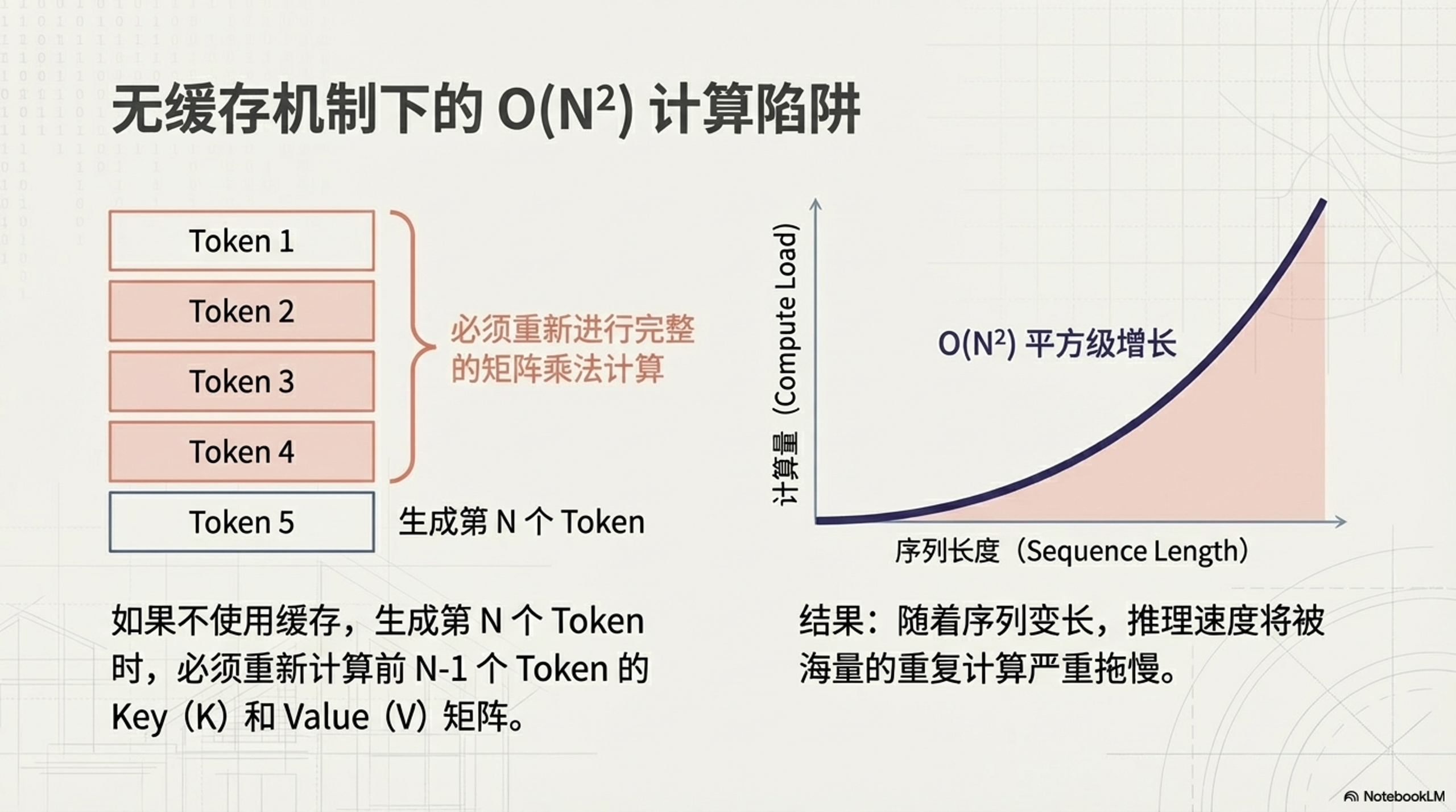
2. KV Cache 核心原理
为了解决自回归生成中的重复计算问题,KV Cache 技术通过“空间换时间”的策略,将已计算过的中间结果存储起来,从而避免了大量冗余的矩阵运算,直接降低了单步推理的计算复杂度。
深入计算过程:本文聚焦 KV Cache 的工作机制和显存分析。如果想从矩阵形状和计算量层面理解 Prefill 为什么是 compute-bound、Decode 为什么是 memory-bound、以及这些差异如何推导出所有 KV Cache 优化方向,见姊妹篇 为什么 GPU 生成每个 token 时利用率不到 5%?——Prefill 与 Decode 深度拆解。
2.1 什么是 KV Cache?
KV Cache 本质上是一种缓存机制,用于存储 Transformer 模型中 Attention 层的 Key 和 Value 矩阵。在推理过程中,模型只需要计算当前新生成 Token 的 Query (Q)、Key (K) 和 Value (V),然后将新的 K 和 V 追加到缓存中。最后,利用当前的 Q 与完整的缓存(历史 K/V + 当前 K/V)进行注意力计算。
为什么只缓存 K/V,不缓存 Q? Q 是「一次性查询」——每个 token 的 Q 只在使用它的那一刻有意义,后续 token 不会再访问。K/V 是被反复检索的「答案库」。详见 KV Cache 为什么叫 KV Cache?——Q 去哪了。
有无 KV Cache 的对比:
2.2 工作流程详解
KV Cache 的工作流程可以分为两个阶段:
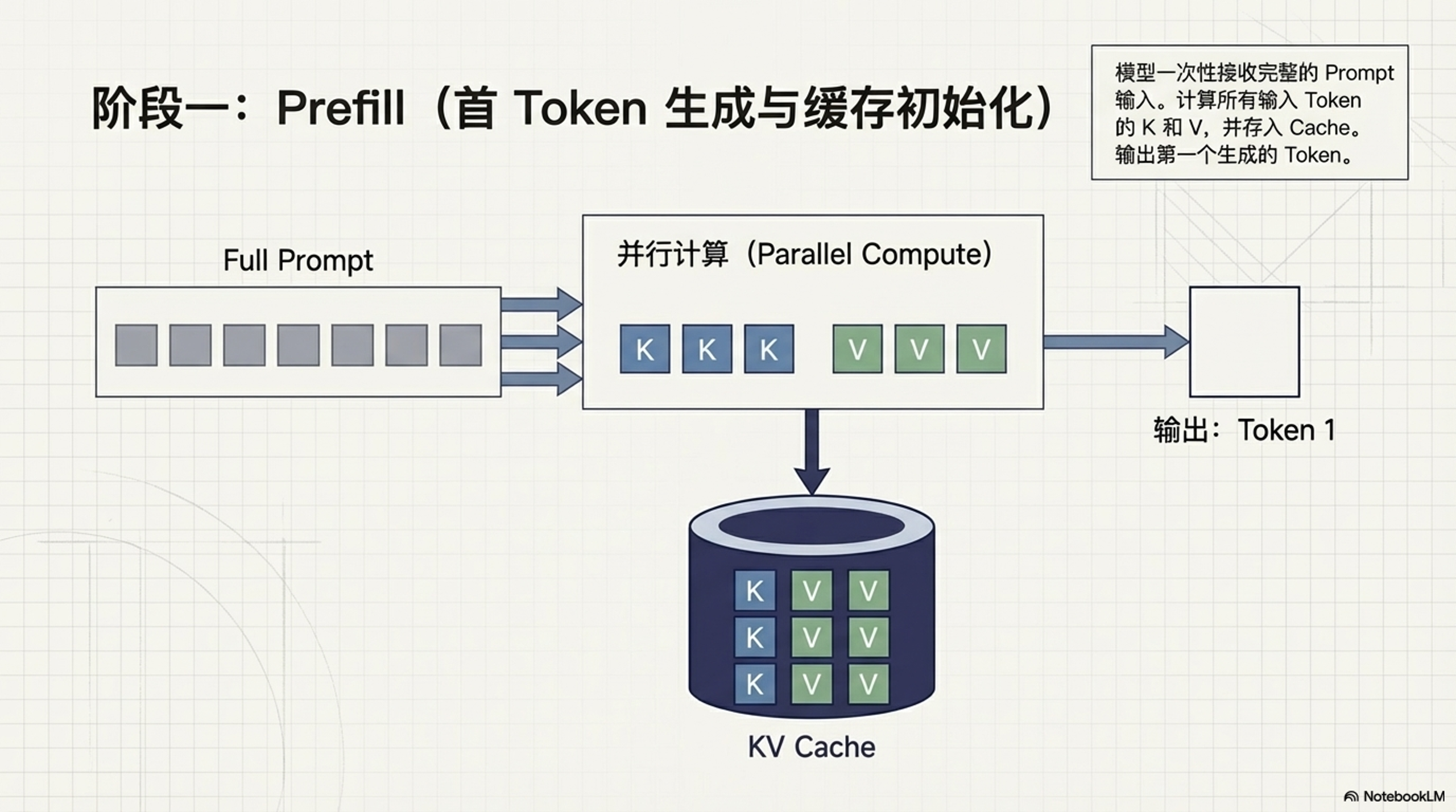
- Prefill 阶段(首 Token 生成):
- 模型接收完整的 Prompt 输入。
- 计算所有输入 Token 的 K 和 V,并将它们存入 Cache。
- 生成第一个输出 Token。
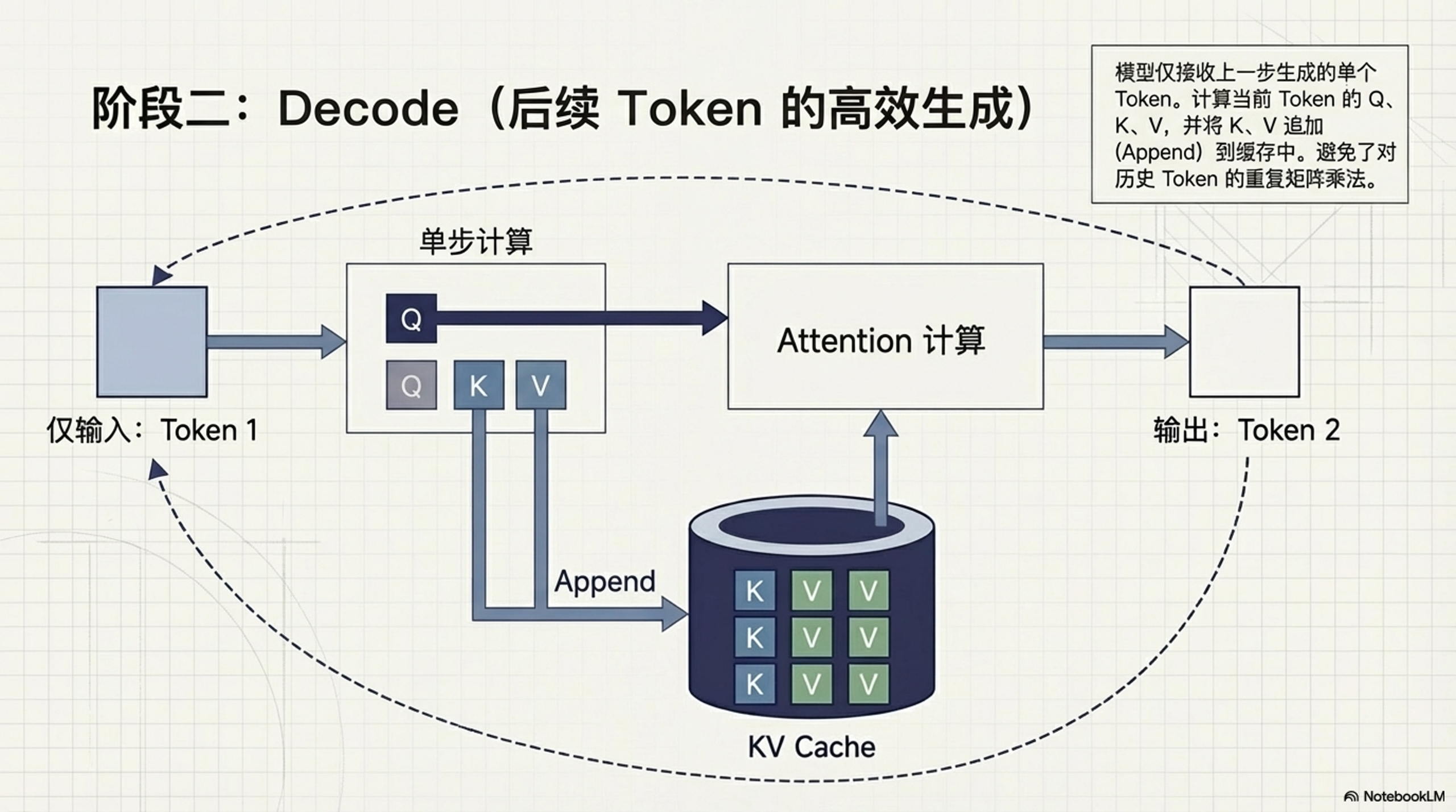
- Decode 阶段(后续 Token 生成):
- 模型仅接收上一步生成的 Token。
- 计算该 Token 的 Q、K、V。
- 将新计算的 K、V 追加(Append)到 Cache 中。
- 利用完整的 Cache (历史 K/V + 当前 K/V) 计算 Attention。
- 生成下一个 Token,循环上述过程。
2.3 伪代码示例
以下是 KV Cache 更新逻辑的简化伪代码表示:
# KV Caching 伪代码示例
# 采用 HuggingFace 常见的 shape 布局:
# [batch_size, seq_len, num_heads, head_dim]
class KVCache:
def __init__(self):
# 初始化空的缓存
self.cache = {"key": None, "value": None}
def update(self, key, value):
"""
更新缓存:将新的 Key 和 Value 追加到现有缓存中
"""
if self.cache["key"] is None:
# 如果缓存为空,直接存储
self.cache["key"] = key
self.cache["value"] = value
else:
# 否则,在 seq_len 维度上进行拼接(该 shape 下 dim=1)
# 注意:具体维度索引取决于不同框架的实现布局
self.cache["key"] = torch.cat([self.cache["key"], key], dim=1)
self.cache["value"] = torch.cat([self.cache["value"], value], dim=1)
def get_cache(self):
return self.cache
以上维度仅为示意。若实现采用 [batch_size, num_heads, seq_len, head_dim] 等其他布局,应将拼接维度相应调整。
3. 显存占用分析
虽然 KV Cache 极大地提升了推理速度,但这种”空间换时间”的做法也带来了显著的显存开销。随着并发请求数(Batch Size)和上下文序列长度的增加,动态增长的缓存数据会占用大量 GPU 显存,成为制约系统吞吐量的核心瓶颈。
如何高效管理 KV Cache? 上述分析解决了”KV Cache 占多少显存”的问题,但另一个同样关键的问题是”怎么存、怎么回收”。传统预分配方案的内存利用率仅 20-40%——大部分显存被碎片浪费。PagedAttention 通过将 KV Cache 切分为固定大小的 block,按需分配、动态映射,将碎片率降到 4% 以下,同等显存可服务 2-4 倍并发。详见 PagedAttention 原理介绍。
详细请参考LLM 模型推理显存占用深度的分析。
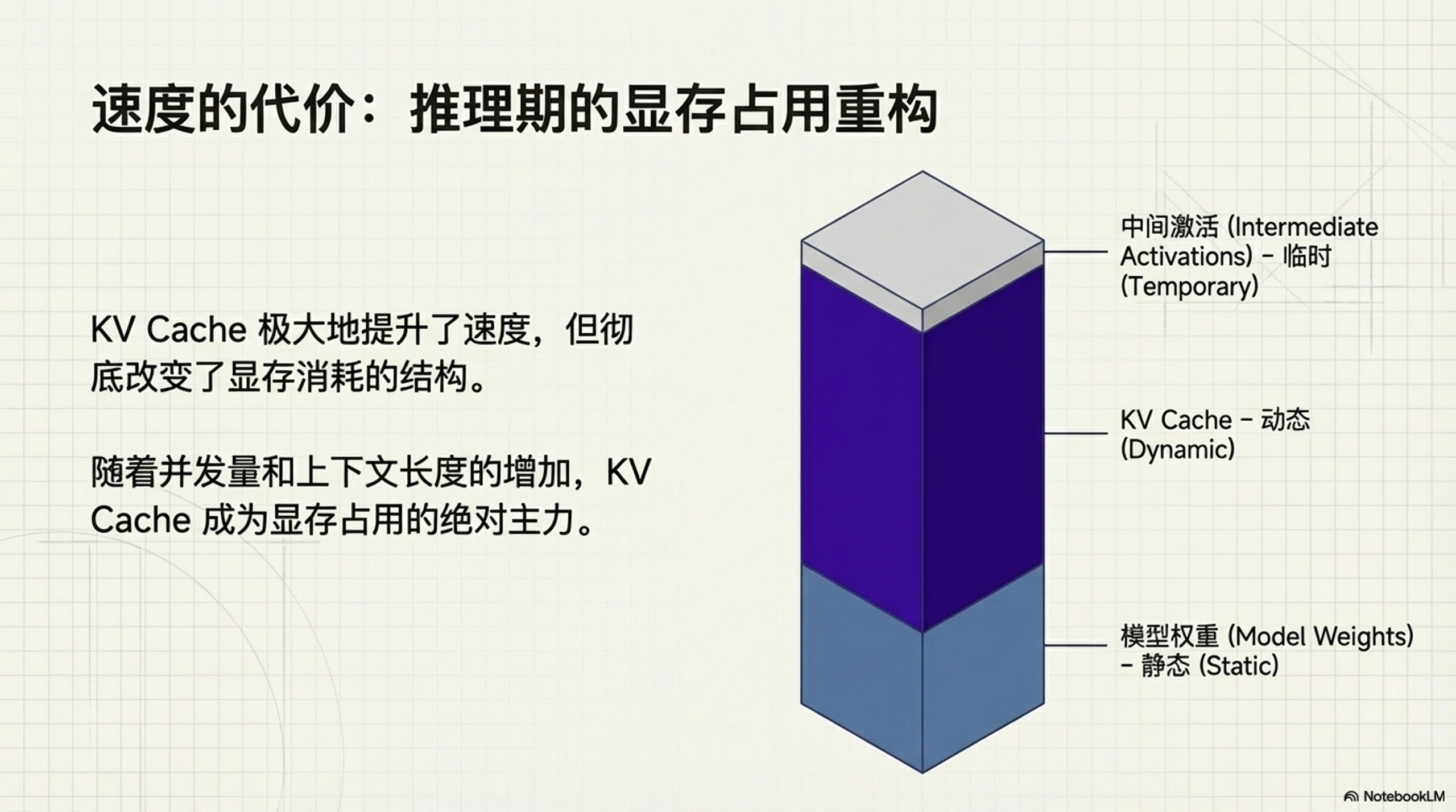
3.1 显存占用的主要构成
在 LLM 推理中,显存主要被以下三部分占用:
- 模型权重 (Model Weights):静态占用,取决于模型参数量和精度。
- KV Cache:动态占用,随着序列长度和 Batch Size 线性增长。
- 中间激活 (Intermediate Activations):推理时的临时计算缓冲区。
3.2 KV Cache 显存计算公式
KV Cache 的显存占用可以通过以下公式估算:
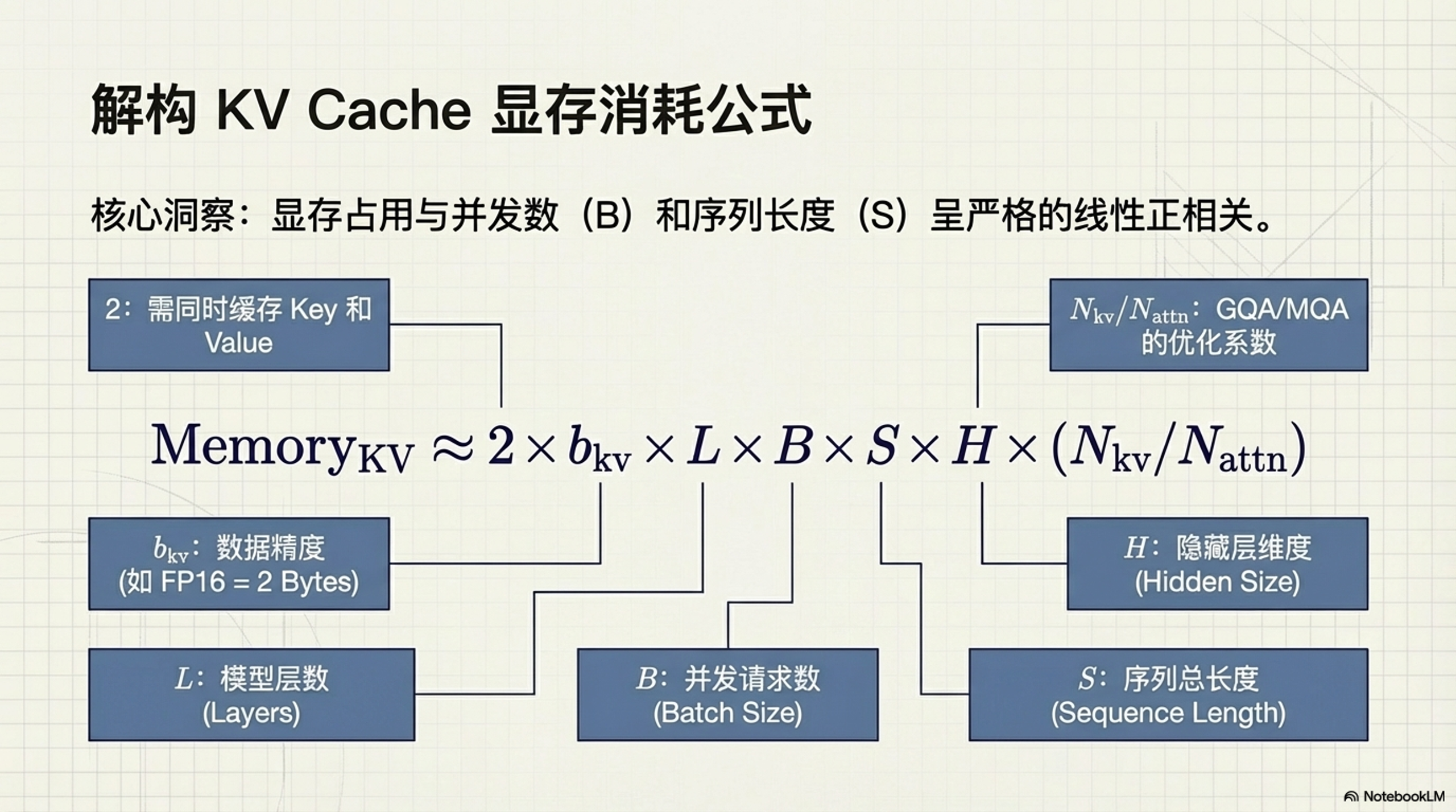
其中:
- $2$:同时缓存 Key 和 Value 矩阵。
- $b_{kv}$:数据精度(Bytes),如 FP16 为 2。
- $L$:模型层数 (Layers)。
- $B$:并发请求数 (Batch Size)。
- $S$:每个请求的平均序列长度(Prompt + 已生成 Token)。
- $H$:隐藏层维度 (Hidden Size)。
- $N_{kv}$:KV Head 的数量(GQA/MQA 中的分组数)。
- $N_{attn}$:Query Head 的数量(总注意力头数)。当使用 MHA 时 $N_{kv} = N_{attn}$,系数为 1。
3.3 Batch Size 对 KV Cache 的影响
上面 $B$ 这个参数经常被初学者忽略——”我先算好 per-token 的 KV Cache,乘以序列长度,就得到显存占用了”。这个算法在 batch=1 时是对的,但在真实推理服务中,多个请求是并发处理的,每个请求都需要自己独立的 KV Cache。
逐级展开公式:
\[\begin{aligned} \text{per\_token} &= 2 \times b_{kv} \times L \times \frac{H \times N_{kv}}{N_{attn}} \\[4pt] \text{per\_sequence} &= \text{per\_token} \times S \quad \text{(序列长度)} \\[4pt] \text{total} &= \text{per\_sequence} \times B \quad \text{(并发请求数)} \end{aligned}\]以 Qwen2.5-7B(L=28, H_kv=4, head_dim=128, FP16)为例:
\[\text{per\_token} = 2 \times 2 \times 28 \times 4 \times 128 \div (1024) \approx 56\ \text{KB}\]| batch | seq_len | total_tokens | KV Cache | 与模型权重 (14 GB) 对比 |
|---|---|---|---|---|
| 1 | 2,048 | 2,048 | 0.11 GB | < 1% |
| 1 | 8,192 | 8,192 | 0.45 GB | 3% |
| 1 | 32,768 | 32,768 | 1.8 GB | 13% |
| 8 | 2,048 | 16,384 | 0.9 GB | 6% |
| 8 | 8,192 | 65,536 | 3.6 GB | 26% |
| 8 | 32,768 | 262,144 | 14.3 GB | ≈ 模型权重 |
| 32 | 2,048 | 65,536 | 3.6 GB | 26% |
| 32 | 8,192 | 262,144 | 14.3 GB | ≈ 模型权重 |
| 32 | 32,768 | 1,048,576 | 57 GB | 4× 模型权重 |
batch=32, seq_len=32768 时,KV Cache(57 GB)是模型权重(14 GB)的 4 倍。 这意味着即使 GPU 能装下模型,也可能因为并发请求的 KV Cache 撑爆显存。
再看 Qwen2.5-72B(L=80, H_kv=8, head_dim=128, FP16,模型权重 ~144 GB):
\[\text{per\_token} = 2 \times 2 \times 80 \times 8 \times 128 \div (1024) = 320\ \text{KB}\]| batch | seq_len | KV Cache |
|---|---|---|
| 1 | 32,768 | 10 GB |
| 4 | 32,768 | 40 GB |
| 8 | 32,768 | 80 GB ← 一张 H100 仅 KV Cache 就满了 |
| 16 | 32,768 | 160 GB ← KV Cache 超过模型权重 |
核心结论:
- Batch Size 不是”免费”的:b=1 时 KV Cache 占比很小,但 b=32 时长上下文场景 KV Cache 远超模型权重,成为显存的真正瓶颈。
- 长上下文 + 大 batch = KV Cache 爆炸:两者是乘法关系($S \times B$),任何一项增大都会等比例放大显存压力。
- 优化方向由此展开:减少 per-token(量化、GQA/MLA)、减少并发 Cache(Offloading)、减少重复 Cache(Prefix Caching)——所有 KV Cache 优化策略都是为了在有限的 GPU 显存中容纳更多的 $S \times B$。
动手验证:本文所有数值可由
kv_cache_calc.py复现。修改--seq-len和--batch参数,观察不同配置下的显存占用变化。
4. 优缺点对比与权衡
引入 KV Cache 从根本上改变了模型推理的性能特征。在实际应用中,系统架构师需要在计算速度的显著提升与显存资源的急剧消耗之间寻找最佳平衡点,不同的业务场景对这种权衡有着完全不同的偏好。
4.1 速度与显存的 Trade-off
在评估是否引入缓存机制时,需要清晰地认识到计算效率与内存消耗之间的反向关系,以下表格直观展示了两者在不同维度的核心差异。
| 特性 | 标准推理 (Standard Inference) | KV Caching |
|---|---|---|
| 单步计算量 | 随序列长度平方级增长 ($O(N^2)$) | 随序列长度线性增长 ($O(N)$) |
| 显存占用 | 较低,主要取决于模型权重 | 较高,随序列长度线性增加 |
| 推理速度 | 随生成长度增加显著变慢 (计算瓶颈) | 速度快且相对稳定 (显存带宽瓶颈) |
| 适用场景 | 短文本、显存极其受限的场景 | 长文本生成、高吞吐服务 |
说明:上表中的“单步计算量”指标针对的是 Decode 阶段生成单个 Token 的场景。若估算生成 $L_{gen}$ 个 Token 的累计复杂度,无 KV Cache 近似为 $O(L_{gen}^3)$;有 KV Cache 时通常近似为 $O(P^2 + P \cdot L_{gen} + L_{gen}^2)$(其中 $P$ 为 Prompt 长度,$P^2$ 来自 Prefill)。
4.2 为什么 KV Cache 是必须的?
对于现代 LLM 应用(如 RAG、长文档摘要),上下文长度往往达到 32k 甚至 128k。如果不使用 KV Cache,生成延迟将变得难以接受。因此,KV Cache 已成为所有主流推理框架(如 vLLM, HuggingFace Transformers)的标准配置。
5. 进阶:降低 KV Cache 开销——从注意力机制入手
KV Cache 的显存占用与注意力头数成正比。标准 MHA 下每个 Q head 都有独立的 K/V head,KV Cache 需要存储全部 K/V。如果在注意力层面让多个 Q head 共享一组 K/V——在不改变模型总参数量的前提下减少需要缓存的 K/V 数量——KV Cache 就会成倍缩小。这就是 MQA 和 GQA 的核心思路:它们首先是注意力机制的架构设计,KV Cache 减小是其对推理最直接的收益。
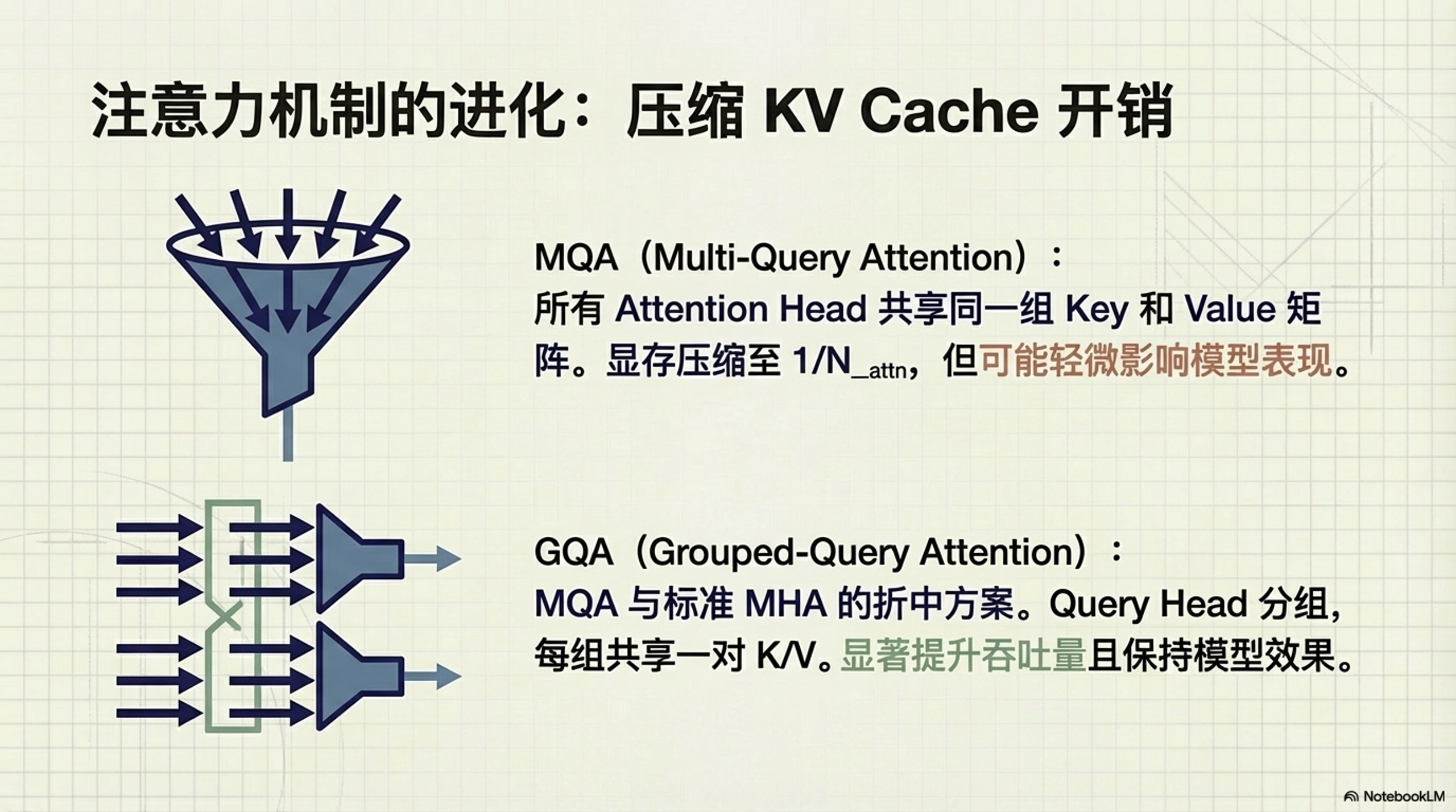
5.1 Multi-Query Attention (MQA)
MQA 让所有的 Attention Head 共享同一组 Key 和 Value 矩阵,从而将 KV Cache 的大小压缩到原来的 $1/N_{attn}$。这极大地降低了显存占用,但可能会轻微影响模型性能。
5.2 Grouped-Query Attention (GQA)
GQA 是 MQA 和标准 MHA (Multi-Head Attention) 的折中方案。它将 Query Head 分组,每组共享一对 K/V Head。例如,Llama-2-70B 就使用了 GQA,显著提升了推理吞吐量,同时保持了较好的模型效果。
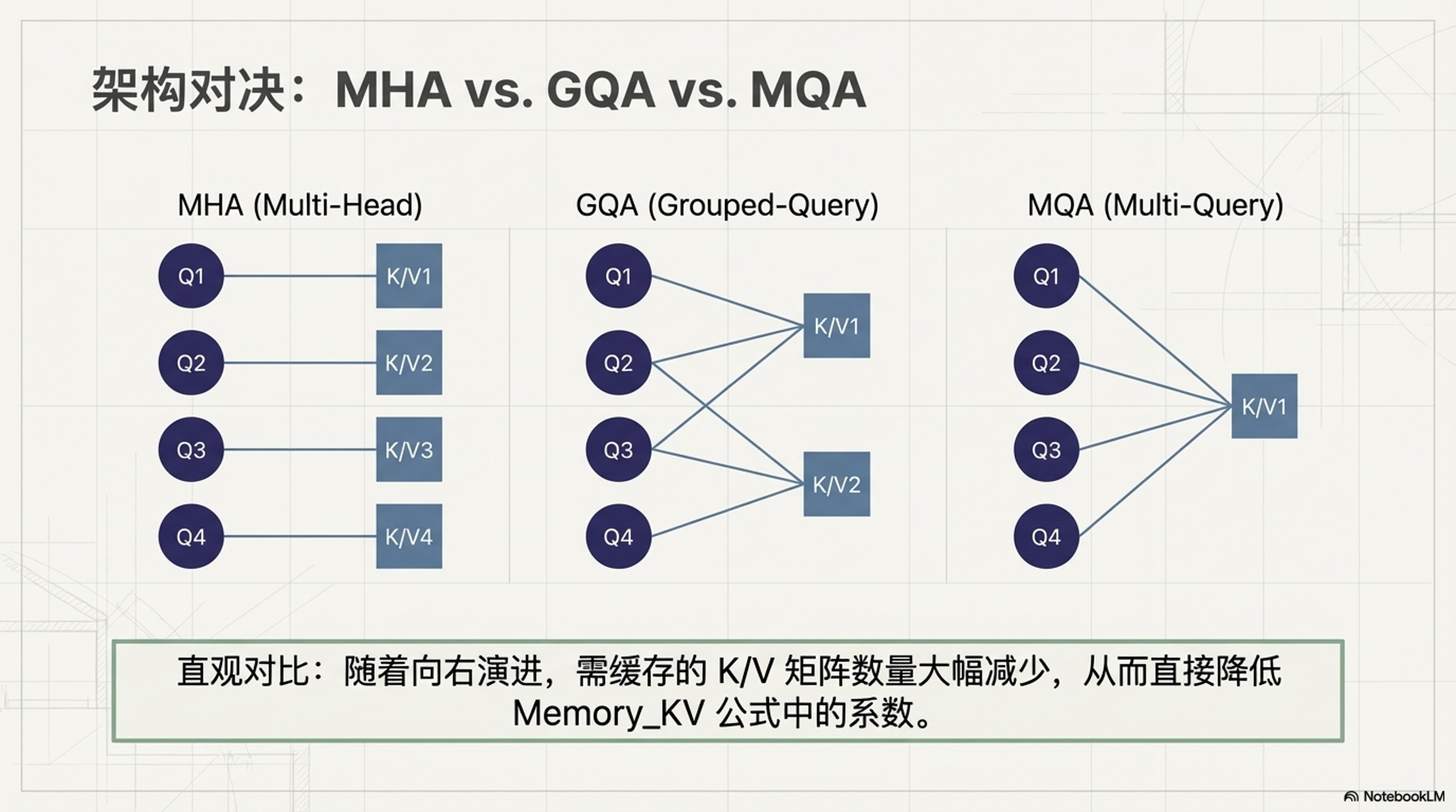
不同注意力机制的 Head 对应关系如下:
- MHA (左): 每个 Query Head 都有对应的 Key/Value Head。
- GQA (中): 多个 Query Head 共享一组 Key/Value Head (分组共享)。
- MQA (右): 所有 Query Head 共享同一组 Key/Value Head。
6. 推荐阅读与工程实践
将 KV Cache 技术真正落地到高并发的生产环境中,需要面对内存碎片化、首字延迟(TTFT)与吞吐量的综合博弈。业界已经发展出一系列成熟的系统级优化方案,帮助推理引擎在有限硬件下压榨出极限性能。
6.1 工程实践要点
在真实推理服务中,KV Cache 的优化目标通常不是单一指标,而是综合平衡首字延迟、单 Token 延迟、吞吐与显存成本。以下是最常见的实践方向:
- TTFT / TPOT 指标分拆优化:
- TTFT (Time To First Token) 主要受 Prefill 影响,优化重点是批处理策略、算子融合与高效调度。
- TPOT (Time Per Output Token) 主要受 Decode 影响,优化重点是 KV 访存效率与带宽利用率。
- Paged KV Cache(分页缓存):
- 将连续大块 KV 内存切分为页,按需分配与回收,减少内存碎片。
- 支持更高并发与更灵活的请求调度,是高吞吐推理框架中的常见方案。
- KV Cache 量化(如 FP8 / INT8):
- 通过降低 KV 精度显著减少显存占用与带宽压力。
- 需要在速度、显存收益与精度损失之间做任务级评估。
- 淘汰与窗口策略(Eviction / Sliding Window):
- 对超长上下文可采用滑动窗口、分段摘要或优先级淘汰策略。
- 核心目标是在有限显存下维持可接受的生成质量与系统稳定性。
6.2 推荐阅读与资源
- 姊妹篇: 为什么 GPU 生成每个 token 时利用率不到 5%?——Prefill 与 Decode 深度拆解(交互可视化 · 校验脚本) — 从矩阵形状和计算量层面推导 KV Cache 的数学必然性,以及 compute-bound vs memory-bound 的根因分析。
- 文章: KV Caching Explained (Hugging Face) - 本文的主要参考来源。
- 可视化: KV Caching in LLMs, explained visually - 包含生动的动画演示。
- 论文: GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints - GQA 的原始论文。