SGLang 推理引擎
SGLang 是新一代 LLM 推理框架,以 RadixAttention 前缀缓存和高效调度器著称。本目录收集 SGLang 相关的源码分析、案例研究与可视化演示。
内容索引
- HiCache 深入详解:将 GPU/CPU/分布式后端统一为 L1-L3 缓存,通过 HiRadixTree 与
page_first内存布局实现跨节点零拷贝。系统梳理演进背景、HiRadixTree 元数据拓扑、三种预取策略与三种写回策略、存储后端热插拔控制面,以及容量/异构 TP/PD 一致性/存储成本四维度的架构权衡。 - SGLang KV Pool 管理:物理存储、Radix Tree 索引与请求视图(可视化):基于 v0.5.14 源码,拆解 KV Pool(物理存储)、Radix Tree(逻辑索引)、ReqToTokenPool(请求视图)及其单向数据流循环。涵盖
lock_ref正确性保证、六种 Pool 类型与七种分配器的选择逻辑、page_size全栈贯穿机制,以及 L1→L2→L3 多级逐出与write_through/write_back策略。- KV Cache L1↔L2 数据流深度分析:作为 KV Pool 管理 §6 的深度配套文章,逐操作拆解 write_backup(HBM → L2)、eviction(释放 HBM)、load_back(L2 → HBM)的完整代码路径,包含 backup 连续前缀不变量、逐出三条分支、load_back 阈值/配额检查,以及 write_through vs write_back 的策略权衡与 CXL 场景适配。
- SGLang 调度器:基于 v0.5.14 源码,拆解 Prefill > Decode 优先级决策、
PrefillAdder五种准入预算机制、decode batch 管理与retract_decode内存压力保护,以及 TTFT 的四阶段时序拆解(queue → schedule → forward)。 - SGLang Scaling Pain 超大规模推理调优案例(译自 z.ai blog):利用投机采样定位 PD 分离架构下的 KV Cache 竞态与时序缺陷,覆盖三类异常现象的识别机制、投机采样指标在实时质量监控中的作用,以及 LayerSplit 分层存储在 120K 上下文下 +132% TPS 的探索性收益。
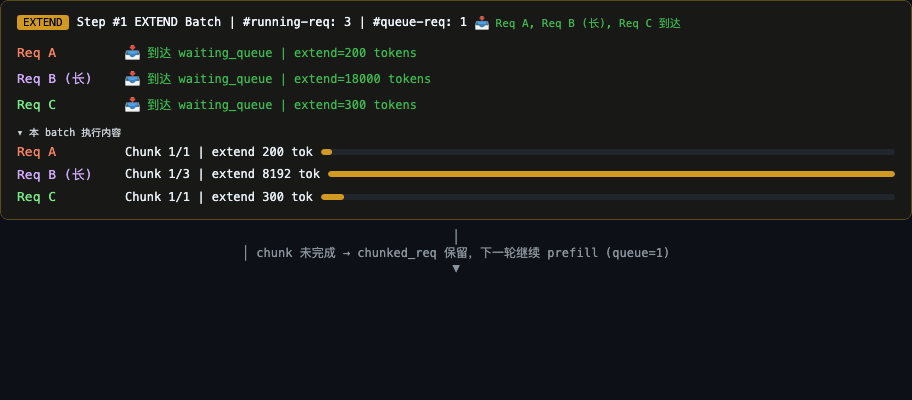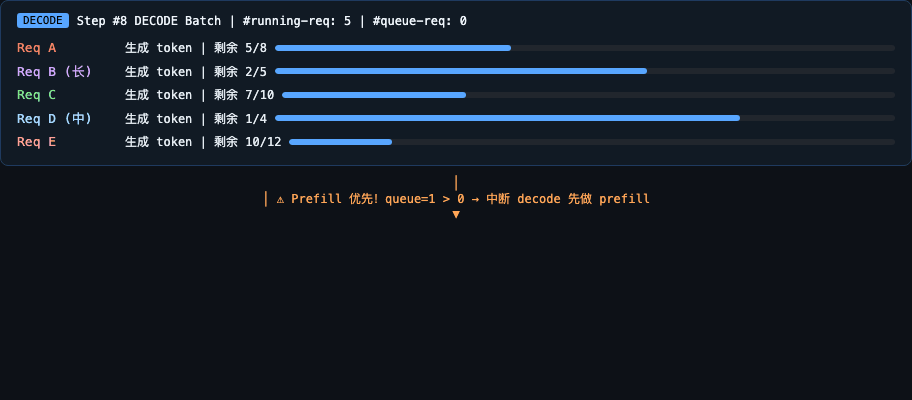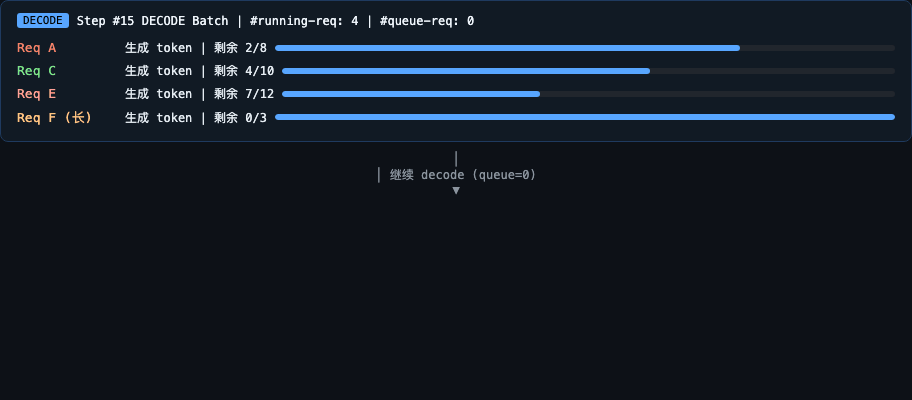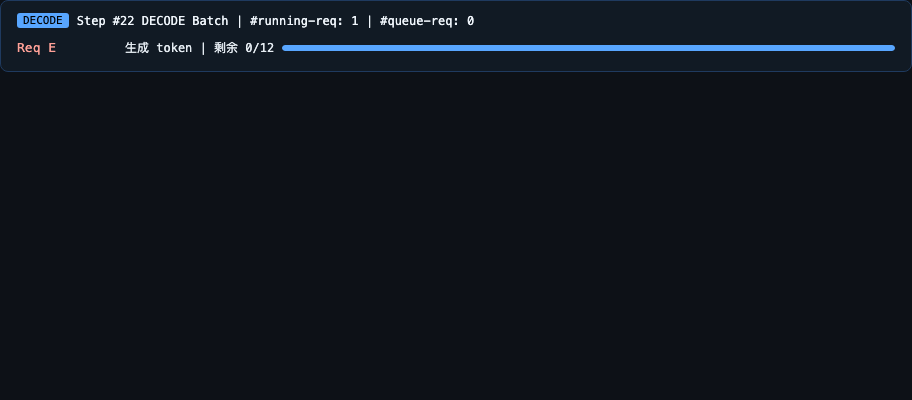
- SGLang Chunked Prefill 原理与代码实现:长 prompt 切分为固定 chunk 与 decode 交替调度的完整机制,涵盖 PrefillAdder 截断逻辑、chunk 间 stash/restore 状态管理、按 GPU 显存自动调参策略,以及 Qwen3.5-122B 8×H100 实测数据(chunk 翻倍 TPS +13.9%)。
- SGLang HiSparse 深度解析:将 DSA 的稀疏选择从 attention kernel 内提升到系统 coordinator 层,通过 page 级选择性加载(
swap_in_selected_pages)、融合 top-k kernel(plan_topk_v2)、双模式索引转换(RAGGED/PAGED)三个设计决策,使稀疏性同时作用于 KV 读取和存储,并作为信号中枢为 DeepGEMM 提供调度元数据。与 vLLM backend 内方案的架构分歧对比。 - SGLang 推理流水线可视化:交互式 Prefill & Decode 流水线演示,展示从 Tokenization、QKV 投影、HiCache RadixTree 前缀匹配、L2→L1 恢复到 Write-back 的完整方法调用栈,覆盖 L1(GPU)/L2(CPU)/L3(NVMe) 三级缓存体系。
- SGLang 调度器可视化(GIF 预览):模拟多请求到达与 Chunked Prefill 调度过程,演示 Prefill 优先策略、Chunked Prefill 截断与续传、Request 生命周期状态转换及 waiting_queue / running-req 的调度队列变化。
{kind=link}