硬件架构与互连技术
快速导航
目录 主题 关键词 对应章节 nvidia/GPU 架构(Volta → Blackwell)、GPGPU vs NPU Tensor Core, HBM, SM §2.1 tpu/Google TPU 脉动阵列架构 Systolic Array, XLA §2.2 pcie/PCIe 协议、拓扑层次、P2PDMA、BAR1、AER Gen3–Gen6, Root Complex §3.1 nvlink/NVLink / NVSwitch 高速互连 1.8 TB/s, GPU-to-GPU §3.2 gpudirect/GPUDirect P2P / RDMA / Storage (GDS) Zero-copy, Bounce Buffer §4.1 / §4.2 / §4.3 superchips/NVLink-C2C、GB300 NVL72 机架级架构 Chip-to-Chip, Rack-Scale §5.1 performance/NUMA 亲和性、延迟金字塔、带宽速查表、AMX vs Tensor Core Latency Hierarchy, Bandwidth §2.3 / §5.2 / §5.3 assets/GPU↔CPU 数据路径、GPU 物理数据路径全景图 Topology Atlas, SVG §6.1 / §6.2
1. 概述
本章沿 芯片 → 总线 → 链路 → 直通 → 系统 五层拓扑解构 AI 服务器算力来源,目标是掌握“从芯片到机架”的瓶颈定位能力:
| 层级 | 关键技术 | 决定的性能维度 | 章节 |
|---|---|---|---|
| 计算芯片 | GPU SM / Tensor Core、TPU 脉动阵列、CPU AMX | 算力密度、片上 SRAM/HBM 访存 | §2 |
| 节点内互连 | PCIe Gen3–Gen6(RC/Switch/Bridge)、NVLink 5 | 卡间 / 卡-外设带宽与延迟 | §3 |
| 跨设备直通 | GPUDirect P2P / RDMA / Storage(GDS) | 是否绕开 CPU Bounce Buffer | §4 |
| 系统级融合 | NVLink-C2C、GB300 NVL72、多 domain NUMA | 部署单位、并行策略、拓扑评估 | §5 |
2. 计算芯片架构
AI 加速器大致沿两条路线发展。一条是以 NVIDIA GPU 为代表的通用路线,用 SIMT 加 Tensor Core 的组合,同时兼顾图形、HPC 和深度学习;另一条是以 Google TPU、各家 NPU 为代表的专用路线,通过脉动阵列或专用矩阵引擎,把每瓦 TOPS 做得更高,但牺牲了灵活性。
2.1 NVIDIA GPU 架构
从 Volta(V100)→ Hopper(H100/H200)→ Blackwell(B200/GB300),每代 GPU 的演进可拆为三条独立轴线,合力决定训练吞吐与推理成本:
| 演进轴 | 走向 | 影响 |
|---|---|---|
| Tensor Core 精度 | FP32 → TF32 → FP8 → FP4 | 单位算力翻倍、量化精度要求收紧 |
| HBM 容量 / 带宽 | HBM2e → HBM3 → HBM3e(HBM4 规划中) | 可承载模型规模、访存是否成为瓶颈 |
| NVLink 代际 | 至 Gen5 单卡 1.8 TB/s | TP / PP 并行可扩展上限 |
延伸阅读:Blackwell 代际已从“单卡”进化为“机架级单域”(NVL72、NVLink-C2C),其部署形态与并行策略影响请参阅 §5.1 AI Superchip 与机架级架构。
- NVIDIA 硬件架构与算力解析(子目录总览):NVIDIA 路线下的导航页,串联 GPU 内部结构与 GPGPU vs NPU 选型两条主线。
- 深入理解 GPU 架构:包含 GPU 与 CPU 的特性对比、内存层次模型(全局内存、共享内存等),以及 Tesla V100、RTX 5000 等具体硬件实例的分析。
- GPGPU vs NPU:大模型推理训练对比:探讨在大语言模型时代,不同架构芯片在训练与推理场景下的优劣势与选型指南。
- MIG 配置与实操:基于 A100 现场查询的 MIG GPU 实例分区实操指南,含 profile 列表、GI/CI 创建命令和 CUDA 设备枚举影响。
2.2 Google TPU 架构
TPU 是 Google 为深度学习量身打造的另一条路径。它的核心思想是用脉动阵列(Systolic Array)把矩阵乘法做到极致,以换取在特定负载下远高于通用 GPU 的能效比。
- TPU 101:深度学习专用加速器架构解析:探索 TPU 的设计哲学、核心计算单元原理及其与 GPU 的差异。
2.3 CPU 矩阵加速:AMX
CPU 侧的矩阵加速同样值得关注。Intel 从 Sapphire Rapids 起引入 AMX (Advanced Matrix Extensions),对标 GPU Tensor Core,在小 batch 推理和实时场景下有延迟优势。
- CPU AMX vs GPU Tensor Core:Intel AMX 与 NVIDIA Tensor Core 的硬件规格对比、适用场景分析与混合计算 Pipeline 设计。
3. 节点内互连:PCIe 与 NVLink
千亿 / 万亿参数规模下,瓶颈从计算转为 内存墙 + IO 墙。互连栈分两层:通用总线 PCIe(含拓扑诊断体系)与 GPU 私有链路 NVLink / NVSwitch。
3.1 PCIe 总线体系
PCIe 是异构通信(CPU↔GPU、GPU↔NIC、GPU↔NVMe)的通用标准,按 协议 → 拓扑 → 运维 三层组织:
协议与基础:
- PCIe 总线技术大全:从物理层到协议层全面解析 PCIe 总线架构及带宽演进。
- Linux PCIe P2PDMA 技术介绍:从 PCIe 硬件机制、Linux 内核实现到 GPUDirect Storage (GDS) 场景实践,全面解析设备直连 DMA 技术。
- GPU BAR1 内存映射:BAR1 窗口大小对 Unified Memory 性能的影响、ReBAR 状态检查、BAR1 vs FB 对比。
拓扑层次与可视化:
- PCIe 拓扑层次:Root Complex → Bridge/Switch → Device 四层模型,从 sysfs 识别各层,本环境 24 domain 完整拓扑。
- PCIe 拓扑可视化:通过 sysfs 和
nvidia-smi交叉验证 GPU 在 PCIe 树中的位置与链路状态。 - PCIe Switch 识别与验证:从 sysfs 区分 Switch vs Bridge 的方法,多端口检测、ACS 验证,本环境确认无 Switch。
运维与诊断:
- PCIe AER 错误监控:sysfs AER 计数器解读、nvidia-smi Replay 监控、链路健康诊断流程与排查指南。
3.2 NVLink 互连
NVLink 是 NVIDIA 专为 GPU 间通信设计的私有链路,Gen5 单卡聚合 1.8 TB/s,带宽 / 延迟 / 拓扑灵活性均领先 PCIe。选型规则:跨设备类型走 PCIe;GPU↔GPU 高带宽低延迟走 NVLink。
- NVLink 技术入门:突破 PCIe 带宽瓶颈的专有高速 GPU 互连方案,含消费级 GPU 不支持 NVLink 的说明。
- NVLink 诊断与实操:
nvidia-smi nvlink命令集、拓扑解读、错误检测,含 A100 实测与 GPU 7 NVLink 故障案例。
4. 跨设备直通:GPUDirect 家族
GPUDirect 让设备间直接 DMA,把 CPU Bounce Buffer 从数据路径上移除——既省带宽又省延迟。三种场景对应三个分支:
| 技术 | 场景 | 数据路径 | 详解 |
|---|---|---|---|
| P2P | 同节点多 GPU | GPU ↔ GPU(经 PCIe/NVLink) | P2P 技术详解 |
| RDMA | 跨节点 | NIC → 远端 GPU VRAM | RDMA 与 Storage 技术详解 |
| Storage (GDS) | 存储加载 | NVMe → GPU VRAM(绕过 CPU) | GDS 基础(GDS 1.13.1 + 3×NVMe 实测) |
5. 系统级融合与性能评估
视角从单颗芯片、单条链路拉升到整台服务器乃至机架,同时补齐贯穿“芯片→链路→机架”的性能评估体系(机器边界 · 拓扑落地性能 · 量级参考)。
5.1 AI Superchip 与机架级架构
Blackwell 代际把 AI 机器边界从“单机”推到“机架级单域”:节点规模 8-GPU HGX → 72-GPU NVL72;封装内 NVLink-C2C 让 CPU/GPU 共享一致性内存,原跨 PCIe 开销被压进芯片。结论:并行策略、显存规划、通信拓扑需以“机架”为新的最小部署单位重新设计。
- NVLink-C2C 详解:基于 Chip-to-Chip 的异构融合互连,打破内存墙的关键。
- NVIDIA GB300 NVL72 架构解析:基于 Blackwell 架构的机架级计算系统设计。
5.2 拓扑与 NUMA 亲和性
互连拓扑的最终落脚点是性能:GPU 插在哪个 PCIe 槽、属于哪个 NUMA node,直接影响 H2D/D2H 带宽和跨 socket 延迟。
- 单卡 GPU 拓扑与 NUMA 深入分析:单 GPU 场景下
nvidia-smi topo -m输出解读、NUMA 亲和性验证与跨 socket 延迟分析(含 taskset 实测数据)。 - 多 PCIe Domain 与 NUMA 映射:Sapphire Rapids 多 domain 架构、BDF 编码的 NUMA 推断、跨 socket PCIe 访问的性能评估。
5.3 性能参考指标
系统访问延迟跨越 5–6 个数量级,是 KV Cache 分层、容量规划、集合通信调度的决策基准——“别让热数据跑到慢介质上”:
| 层级 | 延迟量级 | 相对寄存器倍数 |
|---|---|---|
| 寄存器 / L1 | ~1 ns | 1× |
| HBM | ~100 ns | ~100× |
| 跨节点 RDMA | ~2 μs | ~2,000× |
| NVMe 存储 | ~100 μs | ~100,000× |
- HBM 显存技术演进:从 HBM2 到 HBM3e 的技术迭代,A100 HBM2e vs RTX 5090 GDDR7 实测对比,含 3D 封装原理与 L2 Cache 加速效应。
- AI 基础设施延迟金字塔:寄存器→内存→跨节点网络的各级延迟基准。
- PCIe & NVLink 带宽速查表:PCIe/NVLink 各代带宽、主流 GPU 互连规格、NVMe SSD 速度、典型场景瓶颈。
6. 可视化参考图
将前述抽象拓扑整合为一张“硬件拓扑地图”,覆盖 PCIe 层级、GPUDirect 传统路径 vs GDS 路径、NUMA 影响以及 nvidia-smi topo -m 的 X / PIX / PXB / PHB / NODE / SYS 六级 Peer 分类。
6.1 GPU ↔ CPU 数据路径示意
单机场景下 GPU 访存的完整物理路径:GPU DMA 引擎 → PCIe Endpoint → (PCIe Switch) → Root Complex → Memory Controller → System DRAM。
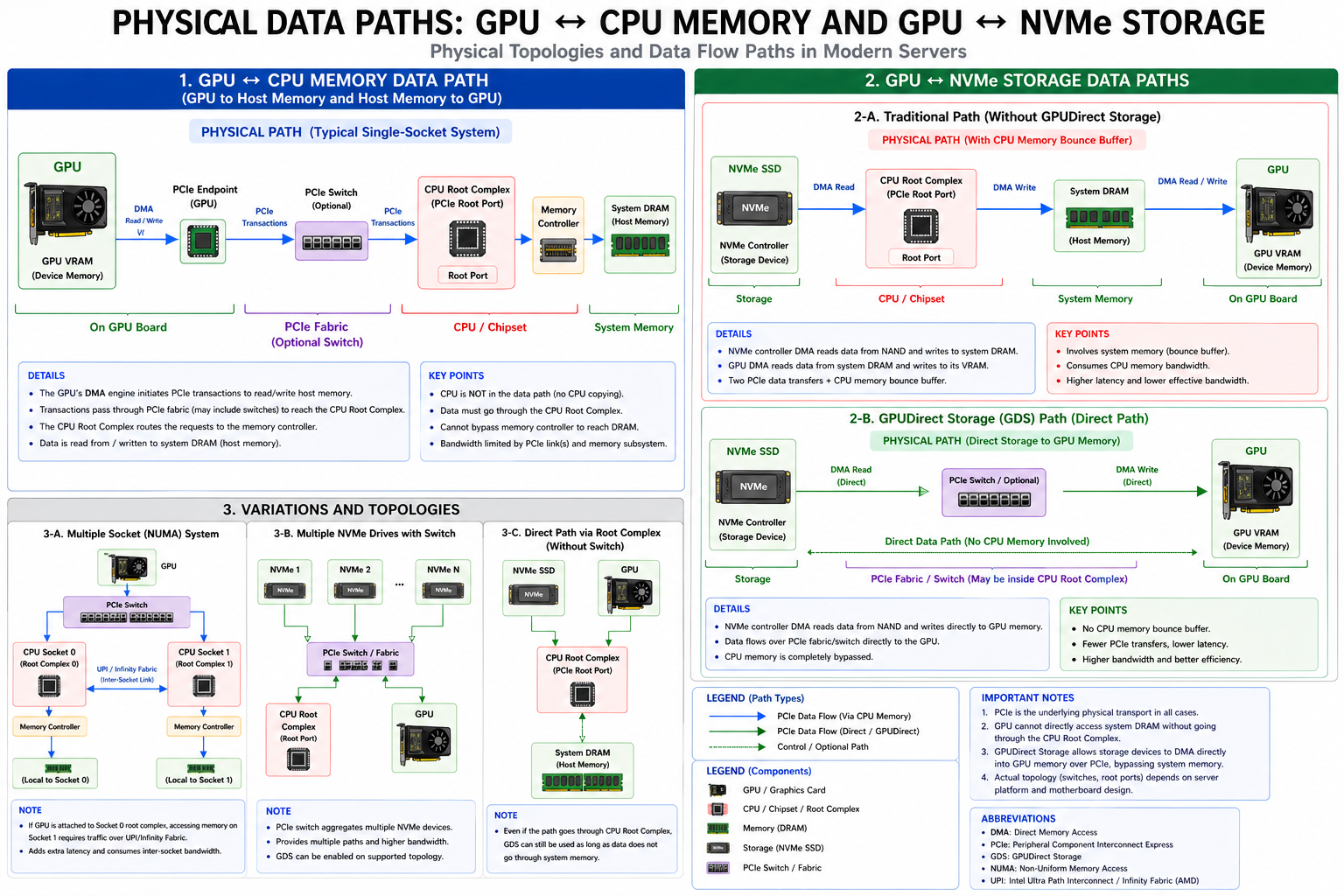
6.2 GPU 物理数据路径全景图
整合注释版全景图,覆盖四个维度:
| 维度 | 要点 |
|---|---|
| GPU ↔ CPU 内存 | 单插槽:PCIe → Root Complex → Memory Controller → DRAM |
| GPU ↔ NVMe 存储 | 对比 Traditional Path(CPU Bounce Buffer)vs GDS Path(存储直达 VRAM) |
| 拓扑变体 | 多插槽 NUMA、多 NVMe + Switch、Root Complex 直连 |
| Peer 拓扑分级 | nvidia-smi topo -m 的 X / PIX / PXB / PHB / NODE / SYS 从优到劣排序,含 P2P 支持状态 |
查看完整 SVG 图(gpu_physical_data_paths.svg)
{kind=link}
说明:矢量图建议浏览器打开。GPUDirect P2P ⊆ PCIe P2PDMA 能力;NVLink(NV#)为独立非 PCIe 通路,不在本图范围内。